Compare commits
13 Commits
1ccbc1d985
...
f796f207ea
| Author | SHA1 | Date | |
|---|---|---|---|
| f796f207ea | |||
| 680c222f9f | |||
| 29024b7061 | |||
| 7e7228bcf4 | |||
| f651e61485 | |||
| d8c0072073 | |||
| 4cb1ab42dc | |||
| dff3bcbd7a | |||
| 71c3e30267 | |||
| 10d7a55454 | |||
| f692f1ed86 | |||
| 0645daa68a | |||
| d060a60480 |
32
.github/workflows/manual.yml
vendored
Normal file
32
.github/workflows/manual.yml
vendored
Normal file
@ -0,0 +1,32 @@
|
||||
# This is a basic workflow that is manually triggered
|
||||
|
||||
name: Manual workflow
|
||||
|
||||
# Controls when the action will run. Workflow runs when manually triggered using the UI
|
||||
# or API.
|
||||
on:
|
||||
workflow_dispatch:
|
||||
# Inputs the workflow accepts.
|
||||
inputs:
|
||||
name:
|
||||
# Friendly description to be shown in the UI instead of 'name'
|
||||
description: 'Person to greet'
|
||||
# Default value if no value is explicitly provided
|
||||
default: 'World'
|
||||
# Input has to be provided for the workflow to run
|
||||
required: true
|
||||
# The data type of the input
|
||||
type: string
|
||||
|
||||
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
|
||||
jobs:
|
||||
# This workflow contains a single job called "greet"
|
||||
greet:
|
||||
# The type of runner that the job will run on
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
# Steps represent a sequence of tasks that will be executed as part of the job
|
||||
steps:
|
||||
# Runs a single command using the runners shell
|
||||
- name: Send greeting
|
||||
run: echo "Hello ${{ inputs.name }}"
|
||||
1
ImageCompress/.gitignore
vendored
Normal file
1
ImageCompress/.gitignore
vendored
Normal file
@ -0,0 +1 @@
|
||||
ffmpeg.7z
|
||||
BIN
ImageCompress/compress/out.png
Normal file
BIN
ImageCompress/compress/out.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 181 KiB |
BIN
ImageCompress/out.png
Normal file
BIN
ImageCompress/out.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 18 KiB |
24
ImageCompress/tmp.py
Normal file
24
ImageCompress/tmp.py
Normal file
@ -0,0 +1,24 @@
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
# 定义初始数组和目标大小
|
||||
arr = np.random.rand(10) * 10 # 随机生成10个在0到10之间的数
|
||||
TARGET_SIZE = 50
|
||||
|
||||
# 计算数组的初始大小和每步的变化量
|
||||
current_size = np.sum(arr)
|
||||
steps = 100 # 逐步逼近的步数
|
||||
scaling_factor = (TARGET_SIZE - current_size) / steps
|
||||
|
||||
# 绘图初始化
|
||||
fig, ax = plt.subplots()
|
||||
line, = ax.plot(arr, marker='o')
|
||||
ax.set_ylim(0, max(arr) + 10)
|
||||
|
||||
# 逐步逼近目标
|
||||
for i in range(steps):
|
||||
arr += scaling_factor * (arr / np.sum(arr)) # 按比例调整数组元素
|
||||
line.set_ydata(arr) # 更新线条数据
|
||||
plt.title(f'Step {i+1}: Size = {np.sum(arr):.2f}')
|
||||
plt.pause(0.1) # 动态显示每一步
|
||||
plt.show()
|
||||
287
VideoCompress/config.py
Normal file
287
VideoCompress/config.py
Normal file
@ -0,0 +1,287 @@
|
||||
import json
|
||||
import os
|
||||
import sys
|
||||
import tkinter as tk
|
||||
from tkinter import ttk, messagebox, filedialog
|
||||
import main as main_program
|
||||
from pathlib import Path
|
||||
|
||||
CONFIG_NAME = Path(sys.path[0])/"config.json"
|
||||
|
||||
DEFAULT_CONFIG = {
|
||||
"crf": 18,
|
||||
"codec": "h264", # could be h264, h264_qsv, h264_nvenc … etc.
|
||||
"ffmpeg": "ffmpeg",
|
||||
"video_ext": [".mp4", ".mkv"],
|
||||
"extra": [],
|
||||
"manual": None,
|
||||
"train": False,
|
||||
}
|
||||
|
||||
HW_SUFFIXES = ["amf", "qsv", "nvenc"]
|
||||
CODECS_BASE = ["h264", "hevc"]
|
||||
preset_options = {
|
||||
"不使用":["","ultrafast","superfast","veryfast","faster","fast","medium","slow","slower","veryslow",],
|
||||
"AMD": ["","speed","balanced","quality",],
|
||||
"Intel": ["","veryfast","faster","fast","medium","slow",],
|
||||
"NVIDIA": ["","default","slow","medium","fast","hp","hq",]
|
||||
}
|
||||
|
||||
|
||||
def config_path() -> str:
|
||||
"""Return path of config file next to the executable / script."""
|
||||
if getattr(sys, "frozen", False): # PyInstaller executable
|
||||
base = os.path.dirname(sys.executable)
|
||||
else:
|
||||
base = os.path.dirname(os.path.abspath(__file__))
|
||||
return os.path.join(base, CONFIG_NAME)
|
||||
|
||||
|
||||
def load_config() -> dict:
|
||||
try:
|
||||
with open(config_path(), "r", encoding="utf-8") as fp:
|
||||
data = json.load(fp)
|
||||
if not isinstance(data, dict):
|
||||
raise ValueError("config.json root must be an object")
|
||||
return {**DEFAULT_CONFIG, **data}
|
||||
except FileNotFoundError:
|
||||
return DEFAULT_CONFIG.copy()
|
||||
except Exception as exc:
|
||||
messagebox.showwarning("FFmpeg Config", f"Invalid config.json – using defaults.\n{exc}")
|
||||
return DEFAULT_CONFIG.copy()
|
||||
|
||||
|
||||
def save_config(cfg: dict):
|
||||
try:
|
||||
with open(config_path(), "w", encoding="utf-8") as fp:
|
||||
json.dump(cfg, fp, ensure_ascii=False, indent=4)
|
||||
except Exception as exc:
|
||||
messagebox.showerror("配置中心", f"保存失败:\n{exc}")
|
||||
else:
|
||||
messagebox.showinfo("配置中心", "保存成功。")
|
||||
|
||||
|
||||
class ConfigApp(tk.Tk):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
# 设置现代化主题和统一内边距
|
||||
style = ttk.Style(self)
|
||||
style.theme_use('clam')
|
||||
self.title("配置中心")
|
||||
self.resizable(False, False)
|
||||
self.cfg = load_config()
|
||||
|
||||
if "-preset" in self.cfg["extra"]:
|
||||
idx = self.cfg["extra"].index("-preset")
|
||||
self.preset = self.cfg["extra"][idx+1]
|
||||
self.cfg["extra"].pop(idx)
|
||||
self.cfg["extra"].pop(idx)
|
||||
else:
|
||||
self.preset = ""
|
||||
|
||||
self._build_ui()
|
||||
# ── helper --------------------------------------------------------------
|
||||
def _grid_label(self, row: int, text: str):
|
||||
tk.Label(self, text=text, anchor="w").grid(row=row, column=0, sticky="w", pady=2, padx=4)
|
||||
|
||||
def _str_var(self, key: str):
|
||||
var = tk.StringVar(value=str(self.cfg.get(key, "")))
|
||||
var.trace_add("write", lambda *_: self.cfg.__setitem__(key, var.get()))
|
||||
return var
|
||||
|
||||
def _bool_var(self, key: str):
|
||||
var = tk.BooleanVar(value=bool(self.cfg.get(key)))
|
||||
var.trace_add("write", lambda *_: self.cfg.__setitem__(key, var.get()))
|
||||
return var
|
||||
|
||||
def _list_var_entry(self, key: str, width: int = 28):
|
||||
"""Comma‑separated list entry bound to config[key]."""
|
||||
var = tk.StringVar(value=",".join(self.cfg.get(key, [])))
|
||||
|
||||
def _update(*_):
|
||||
self.cfg[key] = [s.strip() for s in var.get().split(",") if s.strip()]
|
||||
|
||||
var.trace_add("write", _update)
|
||||
ent = tk.Entry(self, textvariable=var, width=width)
|
||||
return ent
|
||||
|
||||
# ── UI ------------------------------------------------------------------
|
||||
def _build_ui(self):
|
||||
row = 0
|
||||
padx_val = 6
|
||||
pady_val = 4
|
||||
# 编解码器
|
||||
self._grid_label(row, "编解码器 (h264 / hevc)")
|
||||
codec_base = tk.StringVar()
|
||||
codec_base.set(next((c for c in CODECS_BASE if self.cfg["codec"].startswith(c)), "h264"))
|
||||
codec_menu = ttk.Combobox(self, textvariable=codec_base, values=CODECS_BASE, state="readonly", width=10)
|
||||
codec_menu.grid(row=row, column=1, sticky="w", padx=padx_val, pady=pady_val)
|
||||
row += 1
|
||||
|
||||
# 显卡品牌(硬件加速)
|
||||
self._grid_label(row, "GPU加速")
|
||||
accel = tk.StringVar()
|
||||
brand_vals = ["不使用", "NVIDIA", "AMD", "Intel"]
|
||||
def get_brand():
|
||||
codec = self.cfg["codec"]
|
||||
if codec.endswith("_nvenc"):
|
||||
return "NVIDIA"
|
||||
elif codec.endswith("_amf"):
|
||||
return "AMD"
|
||||
elif codec.endswith("_qsv"):
|
||||
return "Intel"
|
||||
return "不使用"
|
||||
accel.set(get_brand())
|
||||
accel_menu = ttk.Combobox(self, textvariable=accel, values=brand_vals, state="readonly", width=10)
|
||||
accel_menu.grid(row=row, column=1, sticky="w", padx=padx_val, pady=pady_val)
|
||||
row += 1
|
||||
|
||||
# CRF或码率选择
|
||||
mode = tk.StringVar(value="crf")
|
||||
if "bitrate" in self.cfg:
|
||||
mode.set("bitrate")
|
||||
def _switch_mode():
|
||||
if mode.get() == "crf":
|
||||
bitrate_ent.configure(state="disabled")
|
||||
crf_ent.configure(state="normal")
|
||||
else:
|
||||
crf_ent.configure(state="disabled")
|
||||
bitrate_ent.configure(state="normal")
|
||||
tk.Radiobutton(self, text="使用 CRF", variable=mode, value="crf", command=_switch_mode).grid(row=row, column=0, sticky="w", padx=padx_val, pady=pady_val)
|
||||
tk.Radiobutton(self, text="使用码率", variable=mode, value="bitrate", command=_switch_mode).grid(row=row, column=1, sticky="w", padx=padx_val, pady=pady_val)
|
||||
row += 1
|
||||
|
||||
# CRF输入框,并在标签中解释参数含义
|
||||
self._grid_label(row, "CRF 值(质量常数,数值越低质量越高)")
|
||||
crf_var = self._str_var("crf")
|
||||
crf_ent = tk.Entry(self, textvariable=crf_var, width=6)
|
||||
crf_ent.grid(row=row, column=1, sticky="w", padx=padx_val, pady=pady_val)
|
||||
row += 1
|
||||
|
||||
# 码率输入框 (kbit/s)
|
||||
self._grid_label(row, "码率 (例如6M, 200k)")
|
||||
bitrate_var = tk.StringVar(value=str(self.cfg.get("bitrate", "")))
|
||||
def _update_bitrate(*_):
|
||||
if mode.get() == "bitrate":
|
||||
try:
|
||||
self.cfg["bitrate"] = bitrate_var.get().strip()
|
||||
except ValueError:
|
||||
self.cfg.pop("bitrate", None)
|
||||
bitrate_var.trace_add("write", _update_bitrate)
|
||||
bitrate_ent = tk.Entry(self, textvariable=bitrate_var, width=8)
|
||||
bitrate_ent.grid(row=row, column=1, sticky="w", padx=padx_val, pady=pady_val)
|
||||
row += 1
|
||||
|
||||
# 预设选项
|
||||
self._grid_label(row, "预设 (决定压缩的速度和质量)")
|
||||
preset_var = tk.StringVar(value=self.preset)
|
||||
|
||||
def _update_preset_option(*_):
|
||||
preset_menu['values'] = preset_options[accel.get()]
|
||||
preset_menu.set("")
|
||||
def _update_preset(*_):
|
||||
print(preset_var.get())
|
||||
if self.cfg["extra"].count("-preset")>0:
|
||||
idx = self.cfg["extra"].index("-preset")
|
||||
self.cfg["extra"].pop(idx)
|
||||
self.cfg["extra"].pop(idx)
|
||||
if preset_var.get():
|
||||
self.cfg["extra"].extend(["-preset", preset_var.get()])
|
||||
preset_var.trace_add("write", _update_preset)
|
||||
accel.trace_add("write",_update_preset_option)
|
||||
preset_menu = ttk.Combobox(self, textvariable=preset_var, values=preset_options[get_brand()], state="readonly", width=10)
|
||||
preset_menu.grid(row=row, column=1, sticky="w", padx=padx_val, pady=pady_val)
|
||||
row += 1
|
||||
|
||||
# ffmpeg路径
|
||||
self._grid_label(row, "ffmpeg 可执行文件")
|
||||
ffmpeg_var = self._str_var("ffmpeg")
|
||||
ffmpeg_ent = tk.Entry(self, textvariable=ffmpeg_var, width=28)
|
||||
ffmpeg_ent.grid(row=row, column=1, sticky="w", padx=padx_val, pady=pady_val)
|
||||
ttk.Button(self, text="浏览", command=lambda: self._pick_ffmpeg(ffmpeg_var)).grid(row=row, column=2, padx=2, pady=pady_val)
|
||||
row += 1
|
||||
|
||||
# 视频扩展名列表
|
||||
self._grid_label(row, "视频扩展名 (.x,.y)")
|
||||
self._list_var_entry("video_ext").grid(row=row, column=1, sticky="w", padx=padx_val, pady=pady_val)
|
||||
row += 1
|
||||
|
||||
# 额外参数列表
|
||||
self._grid_label(row, "额外参数列表")
|
||||
extra_entry = self._list_var_entry("extra")
|
||||
extra_entry.grid(row=row, column=1, sticky="w", padx=padx_val, pady=pady_val)
|
||||
row += 1
|
||||
|
||||
# 手动参数列表
|
||||
self._grid_label(row, "手动参数列表")
|
||||
manual_var = tk.StringVar(value="" if self.cfg.get("manual") is None else " ".join(self.cfg["manual"]))
|
||||
def _update_manual(*_):
|
||||
txt = manual_var.get().strip()
|
||||
self.cfg["manual"] = None if not txt else txt.split()
|
||||
manual_var.trace_add("write", _update_manual)
|
||||
tk.Entry(self, textvariable=manual_var, width=28).grid(row=row, column=1, sticky="w", padx=padx_val, pady=pady_val)
|
||||
row += 1
|
||||
|
||||
|
||||
|
||||
# 训练模式复选框
|
||||
train_var = self._bool_var("train")
|
||||
tk.Checkbutton(self, text="启用训练(实验性)", variable=train_var).grid(row=row, column=0, columnspan=2, sticky="w", padx=padx_val, pady=pady_val)
|
||||
row += 1
|
||||
|
||||
|
||||
# 按钮
|
||||
ttk.Button(self, text="保存", command=lambda: self._on_save(codec_base, accel, mode)).grid(row=row, column=0, pady=8, padx=padx_val)
|
||||
ttk.Button(self, text="退出", command=self.destroy).grid(row=row, column=1, pady=8)
|
||||
_switch_mode() # 初始启用/禁用
|
||||
|
||||
# ── callbacks -----------------------------------------------------------
|
||||
def _on_save(self, codec_base_var, accel_var, mode_var):
|
||||
# 重构codec字符串,同时处理显卡品牌映射
|
||||
base = codec_base_var.get()
|
||||
brand = accel_var.get()
|
||||
brand_map = {"NVIDIA": "nvenc", "AMD": "amf", "Intel": "qsv", "不使用": ""}
|
||||
if brand != "不使用":
|
||||
self.cfg["codec"] = f"{base}_{brand_map[brand]}"
|
||||
else:
|
||||
self.cfg["codec"] = base
|
||||
# 处理码率和crf的配置
|
||||
if mode_var.get() == "crf":
|
||||
self.cfg.pop("bitrate", None)
|
||||
else:
|
||||
br = self.cfg.get("bitrate", "")
|
||||
if not (br.endswith("M") or br.endswith("k")):
|
||||
messagebox.showwarning("警告", "码率参数可能配置错误。例如:3M, 500k")
|
||||
tmp = self.cfg["extra"]
|
||||
idx = 0
|
||||
if len(tmp) == 0:idx = -1
|
||||
else:
|
||||
while True:
|
||||
if tmp[idx] == "-preset":break
|
||||
elif idx+2==len(tmp):
|
||||
idx = -1
|
||||
break
|
||||
else: idx+=1
|
||||
if idx!=-1:
|
||||
preset = self.cfg["extra"][idx+1]
|
||||
if preset not in preset_options[brand]:
|
||||
messagebox.showwarning("警告", "预设(preset)参数可能配置错误!")
|
||||
|
||||
save_config(self.cfg)
|
||||
|
||||
def _pick_ffmpeg(self, var):
|
||||
path = filedialog.askopenfilename(title="Select ffmpeg executable")
|
||||
if path:
|
||||
var.set(path)
|
||||
|
||||
|
||||
def main():
|
||||
if len(sys.argv) > 1:
|
||||
main_program.main()
|
||||
else:
|
||||
app = ConfigApp()
|
||||
app.mainloop()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
466
VideoCompress/main.py
Normal file
466
VideoCompress/main.py
Normal file
@ -0,0 +1,466 @@
|
||||
import subprocess
|
||||
from pathlib import Path
|
||||
import sys
|
||||
import os
|
||||
import logging
|
||||
from datetime import datetime
|
||||
from time import time
|
||||
from rich.logging import RichHandler
|
||||
from rich.progress import Progress
|
||||
from pickle import dumps, loads
|
||||
import atexit
|
||||
import re
|
||||
|
||||
root = None
|
||||
TRAIN = False
|
||||
ESTI_FILE = Path(sys.path[0])/"esti.out"
|
||||
CFG_FILE = Path(sys.path[0])/"config.json"
|
||||
CFG = {
|
||||
"crf":"18",
|
||||
"bitrate": None,
|
||||
"codec": "h264",
|
||||
"extra": [],
|
||||
"ffmpeg": "ffmpeg",
|
||||
"manual": None,
|
||||
"video_ext": [".mp4", ".mkv"],
|
||||
"train": False
|
||||
|
||||
}
|
||||
esti=None # :tuple[list[int],list[float]]
|
||||
|
||||
def get_cmd(video_path,output_file):
|
||||
if CFG["manual"] is not None:
|
||||
command=[
|
||||
CFG["ffmpeg"],
|
||||
"-hide_banner",
|
||||
"-i", video_path
|
||||
]
|
||||
command.extend(CFG["manual"])
|
||||
command.append(output_file)
|
||||
return command
|
||||
|
||||
if CFG["bitrate"] is not None:
|
||||
command = [
|
||||
CFG["ffmpeg"],
|
||||
"-hide_banner",
|
||||
"-i", video_path,
|
||||
"-vf", "scale=-1:1080",
|
||||
"-c:v", CFG["codec"],
|
||||
"-b:v", CFG["bitrate"],
|
||||
"-r","30",
|
||||
"-y",
|
||||
]
|
||||
else:
|
||||
command = [
|
||||
CFG["ffmpeg"],
|
||||
"-hide_banner",
|
||||
"-i", video_path,
|
||||
"-vf", "scale=-1:1080",
|
||||
"-c:v", CFG["codec"],
|
||||
"-global_quality", str(CFG["crf"]),
|
||||
"-r","30",
|
||||
"-y",
|
||||
]
|
||||
|
||||
command.extend(CFG["extra"])
|
||||
command.append(output_file)
|
||||
return command
|
||||
|
||||
def train_init():
|
||||
global esti_data,TRAIN,data_file
|
||||
data_file = Path("estiminate_data.dat")
|
||||
if data_file.exists():
|
||||
esti_data=loads(data_file.read_bytes())
|
||||
if not isinstance(esti_data,tuple):
|
||||
esti_data=([],[])
|
||||
else:
|
||||
esti_data=([],[])
|
||||
TRAIN=True
|
||||
atexit.register(save_esti)
|
||||
# print(esti_data)
|
||||
|
||||
|
||||
# 配置logging
|
||||
def setup_logging():
|
||||
log_dir = Path("logs")
|
||||
log_dir.mkdir(exist_ok=True)
|
||||
log_file = log_dir / f"video_compress_{datetime.now().strftime('%Y%m%d')}.log"
|
||||
stream = RichHandler(rich_tracebacks=True,tracebacks_show_locals=True)
|
||||
stream.setLevel(logging.INFO)
|
||||
stream.setFormatter(logging.Formatter("%(message)s"))
|
||||
|
||||
file = logging.FileHandler(log_file, encoding='utf-8')
|
||||
file.setLevel(logging.DEBUG)
|
||||
|
||||
logging.basicConfig(
|
||||
level=logging.DEBUG,
|
||||
format='%(asctime)s - %(levelname) 7s - %(message)s',
|
||||
handlers=[
|
||||
file,
|
||||
stream
|
||||
]
|
||||
)
|
||||
|
||||
def polyfit_manual(x, y, degree=2):
|
||||
"""手动实现二次多项式最小二乘拟合"""
|
||||
n = len(x)
|
||||
if n != len(y):
|
||||
raise ValueError("输入的x和y长度必须相同")
|
||||
|
||||
# 对于二次多项式 y = ax^2 + bx + c
|
||||
# 构建矩阵方程 A * [a, b, c]^T = B
|
||||
# 其中 A = [[sum(x^4), sum(x^3), sum(x^2)],
|
||||
# [sum(x^3), sum(x^2), sum(x)],
|
||||
# [sum(x^2), sum(x), n]]
|
||||
# B = [sum(x^2 * y), sum(x * y), sum(y)]
|
||||
|
||||
# 计算需要的和
|
||||
sum_x = sum(x)
|
||||
sum_x2 = sum(xi**2 for xi in x)
|
||||
sum_x3 = sum(xi**3 for xi in x)
|
||||
sum_x4 = sum(xi**4 for xi in x)
|
||||
sum_y = sum(y)
|
||||
sum_xy = sum(xi*yi for xi, yi in zip(x, y))
|
||||
sum_x2y = sum(xi**2*yi for xi, yi in zip(x, y))
|
||||
|
||||
# 构建矩阵A和向量B
|
||||
A = [
|
||||
[sum_x4, sum_x3, sum_x2],
|
||||
[sum_x3, sum_x2, sum_x],
|
||||
[sum_x2, sum_x, n]
|
||||
]
|
||||
B = [sum_x2y, sum_xy, sum_y]
|
||||
|
||||
# 使用高斯消元法解线性方程组
|
||||
# 将增广矩阵 [A|B] 转换为行阶梯形式
|
||||
AB = [row + [b] for row, b in zip(A, B)]
|
||||
n_rows = len(AB)
|
||||
|
||||
# 高斯消元
|
||||
for i in range(n_rows):
|
||||
# 寻找当前列中最大元素所在的行
|
||||
max_row = i
|
||||
for j in range(i + 1, n_rows):
|
||||
if abs(AB[j][i]) > abs(AB[max_row][i]):
|
||||
max_row = j
|
||||
|
||||
# 交换行
|
||||
AB[i], AB[max_row] = AB[max_row], AB[i]
|
||||
|
||||
# 将当前行主元归一化
|
||||
pivot = AB[i][i]
|
||||
if pivot == 0:
|
||||
raise ValueError("矩阵奇异,无法求解")
|
||||
|
||||
for j in range(i, n_rows + 1):
|
||||
AB[i][j] /= pivot
|
||||
|
||||
# 消元
|
||||
for j in range(n_rows):
|
||||
if j != i:
|
||||
factor = AB[j][i]
|
||||
for k in range(i, n_rows + 1):
|
||||
AB[j][k] -= factor * AB[i][k]
|
||||
|
||||
# 提取结果
|
||||
coeffs = [AB[i][n_rows] for i in range(n_rows)]
|
||||
|
||||
return coeffs # [a, b, c] 对应 ax^2 + bx + c
|
||||
|
||||
def save_esti():
|
||||
try:
|
||||
if len(esti_data[0]) > 0:
|
||||
coeffs = polyfit_manual(esti_data[0], esti_data[1])
|
||||
# 保存为逗号分隔的文本格式
|
||||
ESTI_FILE.write_text(','.join(map(str, coeffs)))
|
||||
except Exception as e:
|
||||
logging.warning("保存估算数据失败")
|
||||
logging.debug("error at save_esti",exc_info=e)
|
||||
|
||||
def fmt_time(t:int) -> str:
|
||||
if t>3600:
|
||||
return f"{t//3600}h {t//60}min {t%60}s"
|
||||
elif t>60:
|
||||
return f"{t//60}min {t%60}s"
|
||||
else:
|
||||
return f"{round(t)}s"
|
||||
|
||||
def func(sz:int,src=False):
|
||||
if TRAIN:
|
||||
try:
|
||||
data_file.write_bytes(dumps(esti_data))
|
||||
except KeyboardInterrupt as e:raise e
|
||||
except Exception as e:
|
||||
logging.warning("无法保存数据",exc_info=e)
|
||||
try:
|
||||
if TRAIN:
|
||||
if len(esti_data[0])==0:
|
||||
return -1 if src else "NaN"
|
||||
coeffs = polyfit_manual(esti_data[0], esti_data[1])
|
||||
t = coeffs[0]*sz**2 + coeffs[1]*sz + coeffs[2]
|
||||
elif esti is not None:
|
||||
t = esti[0]*sz**2 + esti[1]*sz + esti[2]
|
||||
# print(t,sz)
|
||||
else:
|
||||
logging.warning(f"Unexpected condition at func->TRAIN")
|
||||
return -1 if src else "NaN"
|
||||
t = round(t)
|
||||
if src:
|
||||
return t
|
||||
return fmt_time(t)
|
||||
except KeyboardInterrupt as e:raise e
|
||||
except Exception as e:
|
||||
logging.warning("无法计算预计时间")
|
||||
logging.debug("esti time exception", exc_info=e)
|
||||
return -1 if src else "NaN"
|
||||
|
||||
def process_video(video_path: Path, update_func=None):
|
||||
global esti_data
|
||||
use=None
|
||||
sz=video_path.stat().st_size//(1024*1024)
|
||||
if esti is not None or TRAIN:
|
||||
use = func(sz,True)
|
||||
logging.info(f"开始处理文件: {video_path.relative_to(root)},大小{sz}M,预计{fmt_time(use)}")
|
||||
else:
|
||||
logging.info(f"开始处理文件: {video_path.relative_to(root)},大小{sz}M")
|
||||
|
||||
|
||||
bgn=time()
|
||||
# 在视频文件所在目录下创建 compress 子目录(如果不存在)
|
||||
compress_dir = video_path.parent / "compress"
|
||||
compress_dir.mkdir(exist_ok=True)
|
||||
|
||||
# 输出文件路径:与原文件同名,保存在 compress 目录下
|
||||
output_file = compress_dir / (video_path.stem + video_path.suffix)
|
||||
if output_file.is_file():
|
||||
logging.warning(f"文件{output_file}存在,跳过")
|
||||
return use
|
||||
|
||||
command = get_cmd(str(video_path.absolute()),output_file)
|
||||
|
||||
try:
|
||||
result = subprocess.Popen(
|
||||
command,
|
||||
stdout=subprocess.PIPE,
|
||||
stderr=subprocess.PIPE,
|
||||
encoding="utf-8",
|
||||
text=True
|
||||
)
|
||||
|
||||
while result.poll() is None:
|
||||
line = " "
|
||||
while result.poll() is None and line[-1:] not in "\r\n":
|
||||
line+=result.stderr.read(1)
|
||||
# print(line[-1])
|
||||
if 'warning' in line.lower():
|
||||
logging.warning(f"[FFmpeg]({video_path}): {line}")
|
||||
elif 'error' in line.lower():
|
||||
logging.error(f"[FFmpeg]({video_path}): {line}")
|
||||
elif "frame=" in line:
|
||||
# print(line,end="")
|
||||
match = re.search(r"frame=\s*(\d+)",line)
|
||||
if match:
|
||||
frame_number = int(match.group(1))
|
||||
if update_func is not None:
|
||||
update_func(frame_number)
|
||||
|
||||
if result.returncode != 0:
|
||||
logging.error(f"处理文件 {video_path} 失败,返回码: {result.returncode},cmd={' '.join(command)}")
|
||||
logging.error(result.stdout)
|
||||
logging.error(result.stderr)
|
||||
else:
|
||||
logging.debug(f"文件处理成功: {video_path} -> {output_file}")
|
||||
|
||||
end=time()
|
||||
if TRAIN:
|
||||
esti_data[0].append(sz)
|
||||
esti_data[1].append(end-bgn)
|
||||
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"执行 ffmpeg 命令时发生异常, 文件:{str(video_path)},cmd={' '.join(command)}",exc_info=e)
|
||||
return use
|
||||
|
||||
def traverse_directory(root_dir: Path):
|
||||
video_extensions = set(CFG["video_ext"])
|
||||
sm=None
|
||||
if esti is not None:
|
||||
logging.info(f"正在估算时间(当存在大量小文件时,估算值将会很离谱)")
|
||||
sm = 0
|
||||
for file in root_dir.rglob("*"):
|
||||
if file.parent.name == "compress":continue
|
||||
if file.is_file() and file.suffix.lower() in video_extensions:
|
||||
sz=file.stat().st_size//(1024*1024)
|
||||
tmp = func(sz,True)
|
||||
if not isinstance(tmp,int):
|
||||
logging.error("无法预估时间,因为预估函数返回非整数")
|
||||
elif tmp == -1:
|
||||
logging.error("无法预估时间,因为预估函数返回了异常")
|
||||
sm += tmp
|
||||
logging.info(f"预估用时:{fmt_time(sm)}")
|
||||
else:
|
||||
# logging.info("正在估算视频帧数,用于显示进度。")
|
||||
with Progress() as prog:
|
||||
task = prog.add_task("正在获取视频信息",total=len(list(root_dir.rglob("*"))))
|
||||
frames = {}
|
||||
for file in root_dir.rglob("*"):
|
||||
prog.advance(task)
|
||||
if file.parent.name == "compress":continue
|
||||
if file.is_file() and file.suffix.lower() in video_extensions:
|
||||
cmd = f'ffprobe -v error -select_streams v:0 -show_entries stream=avg_frame_rate,duration -of default=nokey=1:noprint_wrappers=1 "{str(file)}'
|
||||
proc = subprocess.run(cmd, shell=True, capture_output=True, text=True)
|
||||
if proc.returncode != 0:
|
||||
logging.error(f"无法获取视频信息: {file}, 返回码: {proc.returncode}")
|
||||
frames[file] = 60
|
||||
continue
|
||||
if proc.stdout.strip():
|
||||
avg_frame_rate, duration = proc.stdout.strip().split('\n')
|
||||
tmp = avg_frame_rate.split('/')
|
||||
avg_frame_rate = float(tmp[0]) / float(tmp[1])
|
||||
duration = float(duration)
|
||||
frames[file] = duration * avg_frame_rate
|
||||
|
||||
|
||||
logging.debug(f"开始遍历目录: {root_dir}")
|
||||
# 定义需要处理的视频后缀(忽略大小写)
|
||||
|
||||
with Progress() as prog:
|
||||
task = prog.add_task("总进度",total=sm if sm is not None else sum(frames.values()))
|
||||
for file in root_dir.rglob("*"):
|
||||
if file.parent.name == "compress":continue
|
||||
if file.is_file() and file.suffix.lower() in video_extensions:
|
||||
cur = prog.add_task(f"{file.relative_to(root_dir)}",total=frames[file])
|
||||
with prog._lock:
|
||||
tmp = prog._tasks[task]
|
||||
completed_start = tmp.completed
|
||||
|
||||
def update_progress(x):
|
||||
prog.update(cur,completed=x)
|
||||
prog.update(task, completed=completed_start+x)
|
||||
|
||||
t = process_video(file,update_progress)
|
||||
|
||||
prog.stop_task(cur)
|
||||
prog.remove_task(cur)
|
||||
if t is None:
|
||||
prog.update(task,completed=completed_start+frames[file])
|
||||
else:
|
||||
prog.advance(task,t)
|
||||
|
||||
def test():
|
||||
os.environ["PATH"] = Path(__file__).parent.as_posix() + os.pathsep + os.environ["PATH"]
|
||||
|
||||
try:
|
||||
subprocess.run([CFG["ffmpeg"],"-version"],stdout=-3,stderr=-3).check_returncode()
|
||||
except Exception as e:
|
||||
print(__file__)
|
||||
logging.critical("无法运行ffmpeg")
|
||||
exit(-1)
|
||||
try:
|
||||
ret = subprocess.run(
|
||||
"ffmpeg -hide_banner -f lavfi -i testsrc=duration=1:size=1920x1080:rate=30 -c:v libx264 -y -pix_fmt yuv420p compress_video_test.mp4",
|
||||
stdout=subprocess.PIPE,
|
||||
stderr=subprocess.PIPE,
|
||||
text=True
|
||||
)
|
||||
if ret.returncode != 0:
|
||||
logging.warning("无法生成测试视频.")
|
||||
logging.debug(ret.stdout)
|
||||
logging.debug(ret.stderr)
|
||||
ret.check_returncode()
|
||||
cmd = get_cmd("compress_video_test.mp4","compressed_video_test.mp4",)
|
||||
ret = subprocess.run(
|
||||
cmd,
|
||||
stdout=subprocess.PIPE,
|
||||
stderr=subprocess.PIPE,
|
||||
text=True
|
||||
)
|
||||
if ret.returncode != 0:
|
||||
logging.error("测试视频压缩失败")
|
||||
logging.debug(ret.stdout)
|
||||
logging.debug(ret.stderr)
|
||||
logging.error("Error termination via test failed.")
|
||||
exit(-1)
|
||||
os.remove("compress_video_test.mp4")
|
||||
os.remove("compressed_video_test.mp4")
|
||||
except Exception as e:
|
||||
if os.path.exists("compress_video_test.mp4"):
|
||||
os.remove("compress_video_test.mp4")
|
||||
logging.warning("测试未通过,继续运行可能出现未定义行为。")
|
||||
logging.debug("Test error",exc_info=e)
|
||||
|
||||
def init_train():
|
||||
global esti
|
||||
if CFG["train"]:
|
||||
train_init()
|
||||
else:
|
||||
if ESTI_FILE.exists():
|
||||
try:
|
||||
# 从文件读取系数
|
||||
coeffs_str = ESTI_FILE.read_text().strip().split(',')
|
||||
esti = [float(coeff) for coeff in coeffs_str]
|
||||
except Exception as e:
|
||||
logging.warning(f"预测输出文件{str(ESTI_FILE)}存在但无法读取", exc_info=e)
|
||||
|
||||
def exit_pause():
|
||||
if os.name == 'nt':
|
||||
os.system("pause")
|
||||
elif os.name == 'posix':
|
||||
os.system("read -p 'Press Enter to continue...'")
|
||||
|
||||
def main(_root = None):
|
||||
|
||||
atexit.register(exit_pause)
|
||||
|
||||
global root, esti
|
||||
setup_logging()
|
||||
tot_bgn = time()
|
||||
logging.info("-------------------------------")
|
||||
logging.info(datetime.now().strftime('Video Compress started at %Y/%m/%d %H:%M'))
|
||||
|
||||
if CFG_FILE.exists():
|
||||
try:
|
||||
import json
|
||||
cfg:dict = json.loads(CFG_FILE.read_text())
|
||||
CFG.update(cfg)
|
||||
except Exception as e:
|
||||
logging.warning("Invalid config file, ignored.")
|
||||
logging.debug(e)
|
||||
|
||||
if _root is not None:
|
||||
root = Path(_root)
|
||||
else:
|
||||
# 通过命令行参数传入需要遍历的目录
|
||||
if len(sys.argv) < 2:
|
||||
print(f"用法:python {__file__} <目标目录>")
|
||||
logging.warning("Error termination via invalid input.")
|
||||
sys.exit(1)
|
||||
root = Path(sys.argv[1])
|
||||
|
||||
if root.name == "compress":
|
||||
logging.critical("请修改目标目录名为非compress。")
|
||||
logging.error("Error termination via invalid input.")
|
||||
sys.exit(1)
|
||||
|
||||
logging.info("开始验证环境")
|
||||
test()
|
||||
|
||||
init_train()
|
||||
|
||||
if not root.is_dir():
|
||||
print("提供的路径不是一个有效目录。")
|
||||
logging.warning("Error termination via invalid input.")
|
||||
sys.exit(1)
|
||||
|
||||
try:
|
||||
traverse_directory(root)
|
||||
tot_end = time()
|
||||
logging.info(f"Elapsed time: {fmt_time(tot_end-tot_bgn)}")
|
||||
logging.info("Normal termination of Video Compress.")
|
||||
except KeyboardInterrupt:
|
||||
logging.warning("Error termination via keyboard interrupt, CHECK IF LAST PROCSSING VIDEO IS COMPLETED.")
|
||||
except Exception as e:
|
||||
logging.error("Error termination via unhandled error, CHECK IF LAST PROCSSING VIDEO IS COMPLETED.",exc_info=e)
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
214
VideoCompress/main_min.py
Normal file
214
VideoCompress/main_min.py
Normal file
@ -0,0 +1,214 @@
|
||||
import subprocess
|
||||
from pathlib import Path
|
||||
import sys
|
||||
import logging
|
||||
from datetime import datetime
|
||||
from time import time
|
||||
import atexit
|
||||
|
||||
root = None
|
||||
CODEC=None
|
||||
|
||||
|
||||
# 配置logging
|
||||
def setup_logging():
|
||||
log_dir = Path("logs")
|
||||
log_dir.mkdir(exist_ok=True)
|
||||
log_file = log_dir / f"video_compress_{datetime.now().strftime('%Y%m%d')}.log"
|
||||
stream = logging.StreamHandler()
|
||||
stream.setLevel(logging.DEBUG)
|
||||
stream.setFormatter(logging.Formatter("%(message)s"))
|
||||
|
||||
file = logging.FileHandler(log_file, encoding='utf-8')
|
||||
file.setLevel(logging.INFO)
|
||||
|
||||
logging.basicConfig(
|
||||
level=logging.DEBUG,
|
||||
format='%(asctime)s - %(levelname) 7s - %(message)s',
|
||||
handlers=[
|
||||
file,
|
||||
stream
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
def process_video(video_path: Path):
|
||||
global esti_data
|
||||
use=None
|
||||
sz=video_path.stat().st_size//(1024*1024)
|
||||
logging.debug(f"开始处理文件: {video_path.relative_to(root)},大小{sz}M")
|
||||
|
||||
|
||||
bgn=time()
|
||||
compress_dir = video_path.parent / "compress"
|
||||
compress_dir.mkdir(exist_ok=True)
|
||||
|
||||
# 输出文件路径:与原文件同名,保存在 compress 目录下
|
||||
output_file = compress_dir / (video_path.stem + video_path.suffix)
|
||||
if output_file.is_file():
|
||||
logging.warning(f"文件{output_file}存在,跳过")
|
||||
return use
|
||||
|
||||
# 4x
|
||||
# command = [
|
||||
# "ffmpeg.exe", # 可以修改为 ffmpeg 的完整路径,例如:C:/ffmpeg/bin/ffmpeg.exe
|
||||
# "-hide_banner", # 隐藏 ffmpeg 的横幅信息
|
||||
# "-i", str(video_path.absolute()),
|
||||
# "-filter:v", "setpts=0.25*PTS", # 设置视频高度为 1080,宽度按比例自动计算
|
||||
# "-filter:a", "atempo=4.0",
|
||||
# "-c:v", "h264_qsv", # 使用 Intel Quick Sync Video 编码
|
||||
# "-global_quality", "28", # 设置全局质量(数值越低质量越高)
|
||||
# "-r","30",
|
||||
# "-preset", "fast", # 设置压缩速度为慢(压缩效果较好)
|
||||
# "-y",
|
||||
# str(output_file.absolute())
|
||||
# ]
|
||||
|
||||
# 1x
|
||||
if CODEC=="h264_amf":
|
||||
command = [
|
||||
"ffmpeg.exe",
|
||||
"-hide_banner", # 隐藏 ffmpeg 的横幅信息
|
||||
"-i", str(video_path.absolute()),
|
||||
"-vf", "scale=-1:1080", # 设置视频高度为 1080,宽度按比例自动计算
|
||||
"-c:v", CODEC, # 使用 Intel Quick Sync Video 编码
|
||||
"-global_quality", "28", # 设置全局质量(数值越低质量越高)
|
||||
"-c:a", "copy", # 音频不做处理,直接拷贝
|
||||
"-r","30",
|
||||
"-y",
|
||||
str(output_file)
|
||||
]
|
||||
else:
|
||||
command = [
|
||||
"ffmpeg.exe",
|
||||
"-hide_banner", # 隐藏 ffmpeg 的横幅信息
|
||||
"-i", str(video_path.absolute()),
|
||||
"-vf", "scale=-1:1080", # 设置视频高度为 1080,宽度按比例自动计算
|
||||
"-c:v", CODEC, # 使用 Intel Quick Sync Video 编码
|
||||
"-global_quality", "28", # 设置全局质量(数值越低质量越高)
|
||||
"-c:a", "copy", # 音频不做处理,直接拷贝
|
||||
"-r","30",
|
||||
"-preset", "slow",
|
||||
"-y",
|
||||
str(output_file)
|
||||
]
|
||||
|
||||
|
||||
try:
|
||||
result = subprocess.run(
|
||||
command,
|
||||
stdout=subprocess.PIPE,
|
||||
stderr=subprocess.PIPE,
|
||||
encoding="utf-8",
|
||||
text=True
|
||||
)
|
||||
|
||||
if result.stderr:
|
||||
for line in result.stderr.splitlines():
|
||||
if 'warning' in line.lower():
|
||||
logging.warning(f"[FFmpeg]({video_path}): {line}")
|
||||
elif 'error' in line.lower():
|
||||
logging.error(f"[FFmpeg]({video_path}): {line}")
|
||||
|
||||
if result.returncode != 0:
|
||||
logging.error(f"处理文件 {video_path} 失败,返回码: {result.returncode},cmd={' '.join(command)}")
|
||||
logging.error(result.stdout)
|
||||
logging.error(result.stderr)
|
||||
else:
|
||||
logging.debug(f"文件处理成功: {video_path} -> {output_file}")
|
||||
|
||||
end=time()
|
||||
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"执行 ffmpeg 命令时发生异常, 文件:{video_path},cmd={' '.join(command)}",exc_info=e)
|
||||
return use
|
||||
|
||||
def traverse_directory(root_dir: Path):
|
||||
video_extensions = {".mp4", ".mkv"}
|
||||
sm=None
|
||||
|
||||
logging.debug(f"开始遍历目录: {root_dir}")
|
||||
|
||||
for file in root_dir.rglob("*"):
|
||||
if file.parent.name == "compress":continue
|
||||
if file.is_file() and file.suffix.lower() in video_extensions:
|
||||
t = process_video(file)
|
||||
|
||||
@atexit.register
|
||||
def exit_handler():
|
||||
subprocess.run("pause", shell=True)
|
||||
|
||||
def _test():
|
||||
try:
|
||||
subprocess.run(f"ffmpeg -f lavfi -i testsrc=size=1280x720:rate=30 -t 1 -y -c:v {CODEC} -pix_fmt yuv420p test.mp4",stdout=-3,stderr=-3).check_returncode()
|
||||
subprocess.run(f"ffmpeg -i test.mp4 -c:v {CODEC} -pix_fmt yuv420p -y test2.mp4",stdout=-3,stderr=-3).check_returncode()
|
||||
return True
|
||||
except subprocess.CalledProcessError:
|
||||
return False
|
||||
finally:
|
||||
Path("test.mp4").unlink(True)
|
||||
Path("test2.mp4").unlink(True)
|
||||
|
||||
if __name__ == "__main__":
|
||||
setup_logging()
|
||||
tot_bgn = time()
|
||||
logging.info("-------------------------------")
|
||||
logging.info(datetime.now().strftime('Video Compress started at %Y/%m/%d %H:%M'))
|
||||
|
||||
try:
|
||||
subprocess.run("ffmpeg.exe -version",stdout=-3,stderr=-3).check_returncode()
|
||||
except subprocess.CalledProcessError:
|
||||
logging.critical("FFmpeg 未安装或不在系统 PATH 中。")
|
||||
sys.exit(1)
|
||||
|
||||
|
||||
if len(sys.argv) < 2:
|
||||
print(f"推荐用法:python {__file__} <目标目录>")
|
||||
root = Path(input("请输入目标目录:"))
|
||||
while not root.is_dir():
|
||||
root = Path(input("请输入目标目录:"))
|
||||
else:
|
||||
root = Path(sys.argv[1])
|
||||
if len(sys.argv) == 3:
|
||||
CODEC=sys.argv[2]
|
||||
logging.info(f"使用编码器因为cmd:{CODEC}")
|
||||
if not root.is_dir():
|
||||
print("提供的路径不是一个有效目录。")
|
||||
logging.warning("Error termination via invalid input.")
|
||||
sys.exit(1)
|
||||
|
||||
if CODEC is None:
|
||||
logging.info("检测可用编码器")
|
||||
try:
|
||||
ret = subprocess.run(["ffmpeg","-codecs"],stdout=subprocess.PIPE,stderr=subprocess.PIPE,text=True)
|
||||
ret.check_returncode()
|
||||
avai = []
|
||||
if "cuda" in ret.stdout:avai.append("cuda")
|
||||
if "amf" in ret.stdout:avai.append("amf")
|
||||
if "qsv" in ret.stdout:avai.append("qsv")
|
||||
avai.append("h264")
|
||||
|
||||
for c in avai:
|
||||
CODEC = "h264_" + c
|
||||
if _test():
|
||||
break
|
||||
if not _test:
|
||||
logging.critical("没有可用的h264编码器。")
|
||||
exit(1)
|
||||
except Exception as e:
|
||||
logging.error("Error termination via unhandled error.",exc_info=e)
|
||||
finally:
|
||||
logging.info(f"使用编码器:{CODEC}")
|
||||
|
||||
try:
|
||||
traverse_directory(root)
|
||||
tot_end = time()
|
||||
logging.info(f"Elapsed time: {(tot_end-tot_bgn)}s")
|
||||
logging.info("Normal termination of Video Compress.")
|
||||
except KeyboardInterrupt:
|
||||
logging.warning("Error termination via keyboard interrupt, CHECK IF LAST PROCSSING VIDEO IS COMPLETED.")
|
||||
except Exception as e:
|
||||
logging.error("Error termination via unhandled error, CHECK IF LAST PROCSSING VIDEO IS COMPLETED.",exc_info=e)
|
||||
|
||||
|
||||
8
VideoCompress/pack.bat
Normal file
8
VideoCompress/pack.bat
Normal file
@ -0,0 +1,8 @@
|
||||
@echo off
|
||||
echo Packing full.
|
||||
nuitka --standalone config.py --enable-plugin=upx --onefile --enable-plugin=tk-inter --include-data-files=ffmpeg.exe=ffmpeg.exe --include-data-files=ffprobe.exe=ffprobe.exe
|
||||
rename config.exe full.exe
|
||||
echo Packing single.
|
||||
nuitka --standalone main.py --enable-plugin=upx --onefile
|
||||
echo Packing config.
|
||||
nuitka --standalone config.py --enable-plugin=upx --onefile --enable-plugin=tk-inter
|
||||
@ -1,3 +0,0 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:1a75e9390541f4b55d9c01256b361b815c1e0a263e2fb3d072b55c2911ead0b7
|
||||
size 14483456
|
||||
@ -18,23 +18,17 @@ class Msg:
|
||||
if msg is None:
|
||||
self.time=0
|
||||
return
|
||||
print(msg)
|
||||
self.id=msg["id"]
|
||||
if msg["metadata"]["is_visually_hidden_from_conversation"]:
|
||||
self.par=0
|
||||
self.time=msg["create_time"]
|
||||
return
|
||||
self.par=msg["metadata"]["parent_id"]
|
||||
self.role=msg["author"]["role"]
|
||||
# self.thinking_time=sub(r"\\[\(\)]","$",msg["thinking_elapsed_secs"])
|
||||
# self.thinking_content=sub(r"\\[\[\]]","$$",msg["thinking_content"])
|
||||
self.content=msg["content"]["parts"][0]
|
||||
self.time=msg["create_time"]
|
||||
self.id=msg["message_id"]
|
||||
self.par=msg["parent_id"]
|
||||
self.role=msg["role"]
|
||||
self.thinking_time=sub(r"\\[\(\)]","$",msg["thinking_elapsed_secs"])
|
||||
self.thinking_content=sub(r"\\[\[\]]","$$",msg["thinking_content"])
|
||||
self.content=msg["content"]
|
||||
self.time=msg["inserted_at"]
|
||||
|
||||
if self.par==None:self.par=0
|
||||
|
||||
inp = data["messages"]
|
||||
# inp = data["data"]["biz_data"]["chat_messages"]
|
||||
inp = data["data"]["biz_data"]["chat_messages"]
|
||||
msgs:list[Msg]=[Msg(None)]
|
||||
|
||||
child:list[list[Msg]]=[[] for _ in range(len(inp)+1)]
|
||||
@ -63,8 +57,7 @@ if not dfs(0):
|
||||
raise RuntimeError("Cannot find latest node in tree.")
|
||||
|
||||
path.pop(0)
|
||||
title = "Conversation"
|
||||
# title = data['data']['biz_data']['chat_session']['title']
|
||||
title = data['data']['biz_data']['chat_session']['title']
|
||||
out=[f"# {title}"]
|
||||
for i in path:
|
||||
resp=[]
|
||||
|
||||
@ -1,3 +0,0 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:249b62caa7922fecea19e69989bb1ff7259cc37d6ce4ee78fb16abce6acb6720
|
||||
size 7066775
|
||||
@ -125,6 +125,8 @@ def decrypt_files():
|
||||
with open(PASSWORD_FILE, "r") as f:
|
||||
password_data = json.load(f)
|
||||
|
||||
suc=True
|
||||
|
||||
for encrypted_key_hex, encrypted_files in password_data.items():
|
||||
encrypted_aes_key = bytes.fromhex(encrypted_key_hex)
|
||||
aes_key = rsa_cipher.decrypt(encrypted_aes_key)
|
||||
@ -136,6 +138,7 @@ def decrypt_files():
|
||||
iv, ciphertext = f.read(16), f.read()
|
||||
except OSError as e:
|
||||
print(f"Cannot read file {file_path}: {e}")
|
||||
suc=False
|
||||
continue
|
||||
except Exception as e:
|
||||
from traceback import print_exc
|
||||
@ -152,9 +155,11 @@ def decrypt_files():
|
||||
f.write(plaintext)
|
||||
|
||||
os.remove(file_path)
|
||||
|
||||
os.remove(PASSWORD_FILE)
|
||||
print("Files decrypted.")
|
||||
if suc:
|
||||
os.remove(PASSWORD_FILE)
|
||||
print("Files decrypted.")
|
||||
else:
|
||||
print("Some files failed to decrypt.")
|
||||
|
||||
def main():
|
||||
if not ENCRYPT_DIR.exists():
|
||||
|
||||
373
libseat/README.md
Normal file
373
libseat/README.md
Normal file
@ -0,0 +1,373 @@
|
||||
# 某校图书馆预约系统分析
|
||||
|
||||
登录界面如图
|
||||

|
||||
|
||||
输入任意账号、密码,正确填验证码,F12抓包。注意到访问`http://[URL]/rest/auth?answer=bmx8&captchaId=qxtd5hl5h8wz`,返回`{"status":"fail","code":"13","message":"登录失败: 用户名或密码不正确","data":null}`且无其他访问,确定为登录API。
|
||||
观察url参数,未发现账号密码;请求为GET不存在data。仔细观察请求体,注意到headers中有username和password,测试证明为账号密码。
|
||||
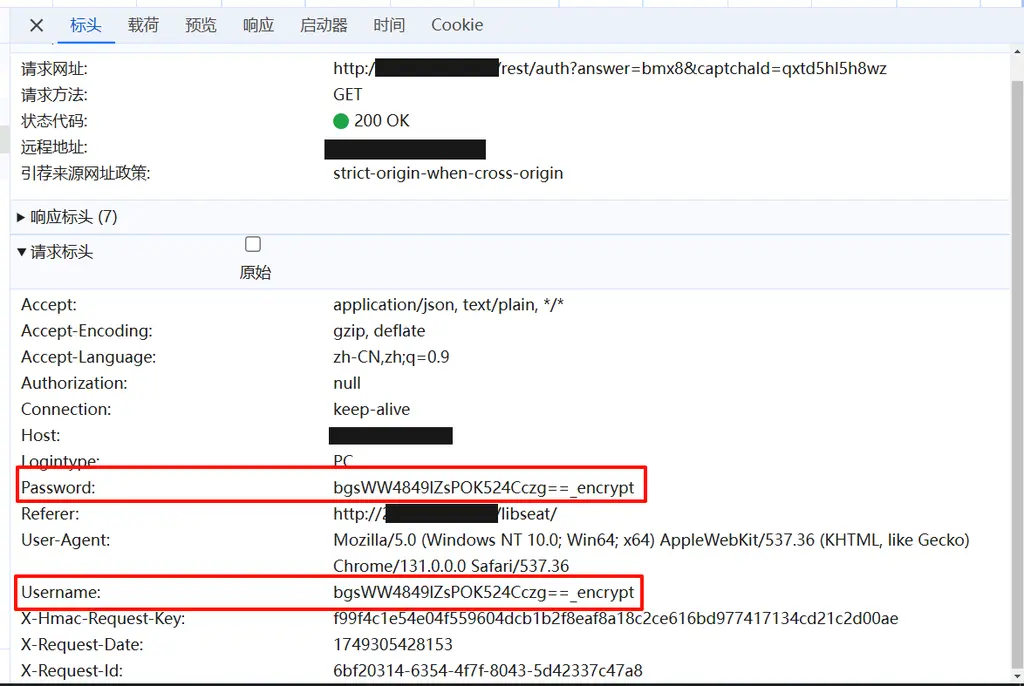
|
||||
显然账号密码加密,尝试直接重放请求失败,注意到headers中的`x-hmac-request-key`等,推测存在加密。
|
||||
|
||||
## headers中的`X-hmac-request-key`等参数
|
||||
|
||||
全局搜索关键字`x-hmac-request-key`,找到唯一代码
|
||||
```javascript
|
||||
{
|
||||
var t = "";
|
||||
t = "post" === e.method ? g("post") : g("get"),
|
||||
e.headers = c()({}, e.headers, {
|
||||
Authorization: sessionStorageProxy.getItem("token"),
|
||||
"X-request-id": t.id,
|
||||
"X-request-date": t.date,
|
||||
"X-hmac-request-key": t.requestKey
|
||||
})
|
||||
}
|
||||
```
|
||||
动态调试找到`g`的实现
|
||||
```
|
||||
function g(e) {
|
||||
var t = function() {
|
||||
for (var e = [], t = 0; t < 36; t++)
|
||||
e[t] = "0123456789abcdef".substr(Math.floor(16 * Math.random()), 1);
|
||||
return e[14] = "4",
|
||||
e[19] = "0123456789abcdef".substr(3 & e[19] | 8, 1),
|
||||
e[8] = e[13] = e[18] = e[23] = "-",
|
||||
e.join("")
|
||||
}()
|
||||
, n = (new Date).getTime()
|
||||
, r = "seat::" + t + "::" + n + "::" + e.toUpperCase()
|
||||
, o = p.a.decrypt(h.default.prototype.$NUMCODE);
|
||||
return {
|
||||
id: t,
|
||||
date: n,
|
||||
requestKey: m.HmacSHA256(r, o).toString()
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
注意到`o = p.a.decrypt(h.default.prototype.$NUMCODE);`未知,确定`h.default.prototype.$NUMCODE`是常量,且`p.a.decrypt`与时间无关,直接动态调试拿到解密结果`o=leos3cr3t`.
|
||||
|
||||
其他算法实现均未引用其他代码,转写为python
|
||||
```python
|
||||
def generate_uuid():
|
||||
hex_digits = '0123456789abcdef'
|
||||
e = [random.choice(hex_digits) for _ in range(36)]
|
||||
e[14] = '4'
|
||||
e[19] = hex_digits[(int(e[19], 16) & 0x3) | 0x8]
|
||||
for i in [8, 13, 18, 23]:
|
||||
e[i] = '-'
|
||||
return ''.join(e)
|
||||
|
||||
def g(e: str):
|
||||
uuid = generate_uuid()
|
||||
timestamp = int(time.time() * 1000)
|
||||
r = f"seat::{uuid}::{timestamp}::{e.upper()}"
|
||||
secret_key = b"leos3cr3t"
|
||||
hmac_obj = hmac.new(secret_key, r.encode('utf-8'), hashlib.sha256)
|
||||
request_key = hmac_obj.hexdigest()
|
||||
return {
|
||||
"id": uuid,
|
||||
"date": timestamp,
|
||||
"requestKey": request_key
|
||||
}
|
||||
```
|
||||
|
||||
至此,使用上述`g`动态生成hmac后,其他内容不变条件下成功重放请求,可以拿到登录token。
|
||||
|
||||
注意到账号密码均加密,尝试逆向。
|
||||
|
||||
## 账号密码加密
|
||||
|
||||
从`http://[URL]/rest/auth?answer=bmx8&captchaId=qxtd5hl5h8wz`请求的启动器中找到关键函数`handleLogin`
|
||||
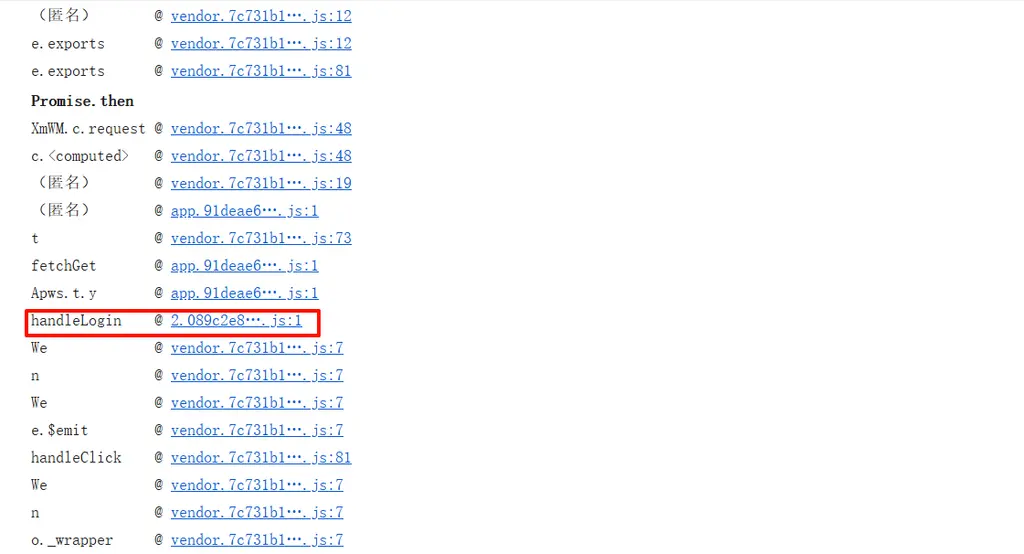
|
||||
```javascript
|
||||
handleLogin: function() {
|
||||
var t = this;
|
||||
if ("" == this.form.username || "" == this.form.password)
|
||||
return this.$alert(this.$t("placeholder.accountInfo"), this.$t("common.tips"), {
|
||||
confirmButtonText: this.$t("common.confirm"),
|
||||
type: "warning",
|
||||
callback: function(t) {}
|
||||
});
|
||||
this.loginLoading = !0,
|
||||
Object(m.y)({
|
||||
username: d(this.form.username) + "_encrypt",
|
||||
password: d(this.form.password) + "_encrypt",
|
||||
answer: this.form.answer,
|
||||
captchaId: this.captchaId
|
||||
}).then(function(s) {
|
||||
"success" == s.data.status ? (sessionStorageProxy.setItem("loginType", "login"),
|
||||
sessionStorageProxy.setItem("token", s.data.data.token),
|
||||
t.loginLoading = !1,
|
||||
t.getUserInfoFunc()) : (t.$warning(s.data.message),
|
||||
t.refreshCode(),
|
||||
t.clearLoginForm(),
|
||||
t.loginLoading = !1)
|
||||
}).catch(function(s) {
|
||||
console.log("出错了:", s),
|
||||
t.$error(t.$t("common.networkError")),
|
||||
t.loginLoading = !1
|
||||
})
|
||||
},
|
||||
```
|
||||
注意到
|
||||
```javascript
|
||||
username: d(this.form.username) + "_encrypt",
|
||||
password: d(this.form.password) + "_encrypt",
|
||||
```
|
||||
动态调试找到`d`的实现
|
||||
```
|
||||
var ....
|
||||
, l = "server_date_time"
|
||||
, u = "client_date_time"
|
||||
, d = function(t) {
|
||||
var s = arguments.length > 1 && void 0 !== arguments[1] ? arguments[1] : l
|
||||
, e = arguments.length > 2 && void 0 !== arguments[2] ? arguments[2] : u
|
||||
, a = r.a.enc.Utf8.parse(e)
|
||||
, i = r.a.enc.Utf8.parse(s)
|
||||
, n = r.a.enc.Utf8.parse(t);
|
||||
return r.a.AES.encrypt(n, i, {
|
||||
iv: a,
|
||||
mode: r.a.mode.CBC,
|
||||
padding: r.a.pad.Pkcs7
|
||||
}).toString()
|
||||
}
|
||||
```
|
||||
显然`arguments.length`恒为1,故`s=l="server_date_time"`,`e=u="client_date_time"`,至此AES加密的参数均已知,python实现该AES加密后验证使用的AES为标准AES加密。
|
||||
故python实现账号密码的加密:
|
||||
```python
|
||||
def encrypt(t, s="server_date_time", e="client_date_time"):
|
||||
key = s.encode('utf-8')
|
||||
iv = e.encode('utf-8')
|
||||
data = t.encode('utf-8')
|
||||
|
||||
cipher = AES.new(key, AES.MODE_CBC, iv)
|
||||
ct_bytes = cipher.encrypt(pad(data, AES.block_size)) # Pkcs7 padding
|
||||
ct_base64 = b64encode(ct_bytes).decode('utf-8')
|
||||
return ct_base64+"_encrypt"
|
||||
```
|
||||
|
||||
关于验证码,`http://[URL]/auth/createCaptcha`返回验证码base64,提交时为URL参数,均未加密。
|
||||
至此,完成整个登录过程的逆向。
|
||||
|
||||
## 其他API
|
||||
|
||||
所有其他API请求headers均带有`X-hmac-request-key`,逻辑同上。URL参数中的token为登录API返回值。
|
||||
|
||||
## 完整demo
|
||||
|
||||
这是一个座位检查demo,查询某个区域是否有余座,如有则通过`serverchan_sdk`发生通知。
|
||||
需按照实际情况修改常量。
|
||||
为了识别验证码,调用了某验证码识别API,该平台为收费API,与本人无关,不对此负责,如有违规烦请告知。
|
||||
|
||||
Github账号出问题了只能直接贴代码了
|
||||
|
||||
```python
|
||||
import time
|
||||
import random
|
||||
import hmac
|
||||
import hashlib
|
||||
import requests
|
||||
from datetime import datetime
|
||||
import json
|
||||
from serverchan_sdk import sc_send;
|
||||
|
||||
|
||||
from Crypto.Cipher import AES
|
||||
from Crypto.Util.Padding import pad
|
||||
from base64 import b64encode
|
||||
|
||||
URL = "http://[your libseat url]"
|
||||
UID = "[uid]" # 图书馆账号
|
||||
PWD = "[password]" # 图书馆密码
|
||||
USERNAME = "[username]" # 验证码平台用户名
|
||||
PASSWORD = "[password]" # 验证码平台密码
|
||||
TOKEN = "[token]"
|
||||
|
||||
def encrypt(t, s="server_date_time", e="client_date_time"):
|
||||
key = s.encode('utf-8')
|
||||
iv = e.encode('utf-8')
|
||||
data = t.encode('utf-8')
|
||||
|
||||
cipher = AES.new(key, AES.MODE_CBC, iv)
|
||||
ct_bytes = cipher.encrypt(pad(data, AES.block_size)) # Pkcs7 padding
|
||||
ct_base64 = b64encode(ct_bytes).decode('utf-8')
|
||||
return ct_base64+"_encrypt"
|
||||
|
||||
def b64_api(username, password, b64, ID):
|
||||
data = {"username": username, "password": password, "ID": ID, "b64": b64, "version": "3.1.1"}
|
||||
data_json = json.dumps(data)
|
||||
result = json.loads(requests.post("http://www.fdyscloud.com.cn/tuling/predict", data=data_json).text)
|
||||
return result
|
||||
|
||||
def recapture():
|
||||
res = requests.get(URL+"/auth/createCaptcha")
|
||||
ret = res.json()
|
||||
im = ret["captchaImage"][21:]
|
||||
result = b64_api(username=USERNAME, password=PASSWORD, b64=im, ID="04897896")
|
||||
return ret["captchaId"],result["data"]["result"]
|
||||
|
||||
def login(username,password):
|
||||
captchaId, ans = recapture()
|
||||
url = URL+"/rest/auth"
|
||||
parm = {
|
||||
"answer": ans.lower(),
|
||||
"captchaId": captchaId,
|
||||
}
|
||||
headers = build_head("post", None)
|
||||
headers.update({
|
||||
"Username": encrypt(username),
|
||||
"Password": encrypt(password),
|
||||
"Logintype": "PC"
|
||||
})
|
||||
res = requests.post(url, headers=headers, params=parm)
|
||||
# print("Status:", res.status_code)
|
||||
ret = res.json()
|
||||
# print("Response:", ret)
|
||||
if ret["status"] == "fail":
|
||||
return None
|
||||
else:
|
||||
return ret["data"]["token"]
|
||||
|
||||
def generate_uuid():
|
||||
hex_digits = '0123456789abcdef'
|
||||
e = [random.choice(hex_digits) for _ in range(36)]
|
||||
e[14] = '4'
|
||||
e[19] = hex_digits[(int(e[19], 16) & 0x3) | 0x8]
|
||||
for i in [8, 13, 18, 23]:
|
||||
e[i] = '-'
|
||||
return ''.join(e)
|
||||
|
||||
def g(e: str):
|
||||
uuid = generate_uuid()
|
||||
timestamp = int(time.time() * 1000)
|
||||
r = f"seat::{uuid}::{timestamp}::{e.upper()}"
|
||||
secret_key = b"leos3cr3t"
|
||||
hmac_obj = hmac.new(secret_key, r.encode('utf-8'), hashlib.sha256)
|
||||
request_key = hmac_obj.hexdigest()
|
||||
return {
|
||||
"id": uuid,
|
||||
"date": timestamp,
|
||||
"requestKey": request_key
|
||||
}
|
||||
|
||||
def build_head(e: str,token:str):
|
||||
sig = g(e)
|
||||
headers = {
|
||||
"Authorization": token,
|
||||
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36",
|
||||
"X-hmac-request-key": sig["requestKey"],
|
||||
"X-request-date": str(sig["date"]),
|
||||
"X-request-id": sig["id"]
|
||||
}
|
||||
if token is None:
|
||||
headers.pop("Authorization")
|
||||
return headers
|
||||
|
||||
def get_floor_data(token: str,buildingId= "1"):
|
||||
date = datetime.now().strftime("%Y-%m-%d") # 获取当前日期
|
||||
url = f"{URL}/rest/v2/room/stats2/{buildingId}/{date}"
|
||||
params = {
|
||||
"buildingId": buildingId,
|
||||
"date": date,
|
||||
"token": token
|
||||
}
|
||||
headers = build_head("get",token)
|
||||
|
||||
response = requests.get(url, headers=headers, params=params)
|
||||
|
||||
print("Status:", response.status_code)
|
||||
res = response.json()
|
||||
if res["status"] != "success":
|
||||
print("Error:", res)
|
||||
return -1
|
||||
else:
|
||||
ret = []
|
||||
for room in res["data"]:
|
||||
ret.append({"roomId": room["roomId"], "room": room["room"], "free": room["free"], "inUse": room["inUse"], "totalSeats": room["totalSeats"]})
|
||||
# print(f"Room ID: {room['roomId']}, Name: {room['room']}, free: {room['free']}, inUse: {room['inUse']}, total: {room['totalSeats']}")
|
||||
return ret
|
||||
|
||||
def get_room_data(token: str,id:str = "10"):
|
||||
date = datetime.now().strftime("%Y-%m-%d") # 获取当前日期
|
||||
# 替换为目标接口地址
|
||||
print(date)
|
||||
url = f"{URL}/rest/v2/room/layoutByDate/{id}/{date}"
|
||||
params = {
|
||||
"id": id,
|
||||
"date": date,
|
||||
"token": token
|
||||
}
|
||||
|
||||
sig = g("get")
|
||||
headers = {
|
||||
"Authorization": token,
|
||||
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36",
|
||||
"X-hmac-request-key": sig["requestKey"],
|
||||
"X-request-date": str(sig["date"]),
|
||||
"X-request-id": sig["id"]
|
||||
}
|
||||
|
||||
response = requests.get(url, headers=headers, params=params)
|
||||
|
||||
print("Status:", response.status_code)
|
||||
ret = response.json()
|
||||
if ret["status"] != "success":
|
||||
print("Error:", ret)
|
||||
return -1
|
||||
else:
|
||||
print("Data:", ret["data"]["name"])
|
||||
print("Response:", )
|
||||
|
||||
def send_message(msg):
|
||||
print(sc_send(TOKEN, "图书馆座位", msg))
|
||||
|
||||
def main(dep=0):
|
||||
if dep>3:
|
||||
print("无法获取数据!")
|
||||
send_message("无法获取数据!")
|
||||
return
|
||||
years = [2021, 2022, 2023, 2024]
|
||||
house = []
|
||||
classes = [1,2,3]
|
||||
num = range(1,21)
|
||||
token = None
|
||||
try:
|
||||
print("正在尝试登录...")
|
||||
tried =0
|
||||
while token is None and tried <= 5:
|
||||
id = UID
|
||||
# id = str(random.choice(years)) + random.choice(house) + str(random.choice(classes)) + str(random.choice(num)).zfill(2)
|
||||
token = login(id,PWD)
|
||||
if token is None:
|
||||
print("登陆失败:",token)
|
||||
time.sleep(random.randint(10, 30))
|
||||
tried += 1
|
||||
if token is None:
|
||||
print("登录失败,请检查账号密码或网络连接。")
|
||||
main(dep+1)
|
||||
return
|
||||
print("登录成功,Token:", token)
|
||||
data = get_floor_data(token, "1") # 获取一楼数据
|
||||
if data == -1:
|
||||
print("获取数据失败,请检查网络连接或Token是否有效。")
|
||||
main(dep+1)
|
||||
else:
|
||||
ret = []
|
||||
for room in data:
|
||||
if room["free"] > 0:
|
||||
ret.append(room)
|
||||
if ret:
|
||||
msg = "|区域|空座|占用率|\n|-|-|-|\n"
|
||||
for room in ret:
|
||||
msg += f"|{room['room']}|{room['free']}|{1-room['free']/room['totalSeats']:0.2f}|\n"
|
||||
send_message(msg)
|
||||
except Exception as e:
|
||||
print("发生错误:", e)
|
||||
main(dep+1)
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
||||
```
|
||||
|
||||
BIN
libseat/image-1.png
Normal file
BIN
libseat/image-1.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 71 KiB |
BIN
libseat/image-2.png
Normal file
BIN
libseat/image-2.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 66 KiB |
BIN
libseat/image.png
Normal file
BIN
libseat/image.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 426 KiB |
116
libseat/inter.py
Normal file
116
libseat/inter.py
Normal file
@ -0,0 +1,116 @@
|
||||
# app.py ── 运行:python app.py
|
||||
import re, threading, datetime as dt
|
||||
from flask import Flask, render_template_string, request, redirect, url_for, flash
|
||||
|
||||
app = Flask(__name__)
|
||||
app.secret_key = "secret"
|
||||
|
||||
# ---------- ❶ 你要周期执行的业务函数 ----------
|
||||
def my_task():
|
||||
print(f"[{dt.datetime.now():%F %T}] 🎉 my_task 被调用")
|
||||
|
||||
# ---------- ❷ 将 “1h / 30min / 45s” 解析为秒 ----------
|
||||
def parse_interval(expr: str) -> int:
|
||||
m = re.match(r"^\s*(\d+)\s*(h|hr|hour|m|min|minute|s|sec)\s*$", expr, re.I)
|
||||
if not m:
|
||||
raise ValueError("格式不正确——示例: 1h、30min、45s")
|
||||
n, unit = int(m[1]), m[2].lower()
|
||||
return n * 3600 if unit.startswith("h") else n * 60 if unit.startswith("m") else n
|
||||
|
||||
# ---------- ❸ 简易调度器 (Thread + Event) ----------
|
||||
class LoopWorker(threading.Thread):
|
||||
def __init__(self, interval_s: int, fn):
|
||||
super().__init__(daemon=True)
|
||||
self.interval_s = interval_s
|
||||
self.fn = fn
|
||||
self._stop = threading.Event()
|
||||
|
||||
def cancel(self):
|
||||
self._stop.set()
|
||||
|
||||
def run(self):
|
||||
while not self._stop.wait(self.interval_s):
|
||||
try:
|
||||
self.fn()
|
||||
except Exception as e:
|
||||
print("任务执行出错:", e)
|
||||
|
||||
worker: LoopWorker | None = None # 全局保存当前线程
|
||||
current_expr: str = "" # 全局保存当前表达式
|
||||
|
||||
# ---------- ❹ Tailwind + Alpine 渲染 ----------
|
||||
PAGE = """
|
||||
<!doctype html>
|
||||
<html lang="zh">
|
||||
<head>
|
||||
<meta charset="UTF-8" />
|
||||
<title>周期设置</title>
|
||||
<script src="https://cdn.tailwindcss.com/3.4.0"></script>
|
||||
</head>
|
||||
<body class="bg-gray-100 min-h-screen flex items-center justify-center">
|
||||
<div class="w-full max-w-md p-8 bg-white rounded-2xl shadow-xl space-y-6"> <header class="flex justify-between items-center">
|
||||
<h1 class="text-2xl font-semibold text-gray-800">周期设置</h1>
|
||||
</header> {% with msgs = get_flashed_messages(with_categories=true) %}
|
||||
{% if msgs %}
|
||||
{% for cat, msg in msgs %}
|
||||
<div class="px-4 py-2 rounded-lg text-sm {{ 'bg-green-100 text-green-800' if cat=='success' else 'bg-red-100 text-red-800' }}">
|
||||
<span>{{ msg }}</span>
|
||||
</div>
|
||||
{% endfor %}
|
||||
{% endif %}
|
||||
{% endwith %}
|
||||
|
||||
<form method="post" class="space-y-4">
|
||||
<input name="interval" required placeholder="例:1h / 30min / 45s"
|
||||
class="w-full px-4 py-2 rounded-lg border border-gray-300 focus:ring-2
|
||||
focus:ring-indigo-400 focus:outline-none"/>
|
||||
<button class="w-full py-2 rounded-lg bg-indigo-600 hover:bg-indigo-500 text-white font-medium">
|
||||
设置周期
|
||||
</button>
|
||||
</form>
|
||||
|
||||
<p class="text-xs text-gray-500">
|
||||
当前任务:<br>
|
||||
{% if worker %}
|
||||
每 {{current_expr}} 触发一次(刷新页面查看最新状态)
|
||||
{% else %}
|
||||
未设置
|
||||
{% endif %}
|
||||
</p>
|
||||
</div>
|
||||
</body>
|
||||
</html>
|
||||
"""
|
||||
|
||||
@app.route("/", methods=["GET", "POST"])
|
||||
def index():
|
||||
global worker, current_expr
|
||||
if request.method == "POST":
|
||||
expr = request.form["interval"].strip()
|
||||
try:
|
||||
if expr == "0":
|
||||
# 如果输入为 "0",则取消当前任务
|
||||
if worker:
|
||||
worker.cancel()
|
||||
worker = None
|
||||
current_expr = ""
|
||||
flash("✅ 已取消定时任务", "success")
|
||||
return redirect(url_for("index"))
|
||||
sec = parse_interval(expr)
|
||||
# 取消旧线程
|
||||
if worker:
|
||||
worker.cancel()
|
||||
# 启动新线程
|
||||
worker = LoopWorker(sec, my_task)
|
||||
worker.start()
|
||||
current_expr = expr # 保存表达式
|
||||
print(expr)
|
||||
flash(f"✅ 已设置:每 {expr} 运行一次 my_task()", "success")
|
||||
except Exception as e:
|
||||
flash(f"❌ {e}", "error")
|
||||
return redirect(url_for("index"))
|
||||
|
||||
return render_template_string(PAGE, worker=worker, current_expr=current_expr)
|
||||
|
||||
if __name__ == "__main__":
|
||||
app.run(debug=True)
|
||||
205
libseat/libseat.py
Normal file
205
libseat/libseat.py
Normal file
@ -0,0 +1,205 @@
|
||||
import time
|
||||
import random
|
||||
import hmac
|
||||
import hashlib
|
||||
import requests
|
||||
from datetime import datetime
|
||||
import json
|
||||
from serverchan_sdk import sc_send;
|
||||
|
||||
|
||||
from Crypto.Cipher import AES
|
||||
from Crypto.Util.Padding import pad
|
||||
from base64 import b64encode
|
||||
|
||||
URL = "http://[your libseat url]"
|
||||
UID = "[uid]" # 图书馆账号
|
||||
PWD = "[password]" # 图书馆密码
|
||||
USERNAME = "[username]" # 验证码平台用户名
|
||||
PASSWORD = "[password]" # 验证码平台密码
|
||||
TOKEN = "[token]"
|
||||
|
||||
def encrypt(t, s="server_date_time", e="client_date_time"):
|
||||
key = s.encode('utf-8')
|
||||
iv = e.encode('utf-8')
|
||||
data = t.encode('utf-8')
|
||||
|
||||
cipher = AES.new(key, AES.MODE_CBC, iv)
|
||||
ct_bytes = cipher.encrypt(pad(data, AES.block_size)) # Pkcs7 padding
|
||||
ct_base64 = b64encode(ct_bytes).decode('utf-8')
|
||||
return ct_base64+"_encrypt"
|
||||
|
||||
def b64_api(username, password, b64, ID):
|
||||
data = {"username": username, "password": password, "ID": ID, "b64": b64, "version": "3.1.1"}
|
||||
data_json = json.dumps(data)
|
||||
result = json.loads(requests.post("http://www.fdyscloud.com.cn/tuling/predict", data=data_json).text)
|
||||
return result
|
||||
|
||||
def recapture():
|
||||
res = requests.get(URL+"/auth/createCaptcha")
|
||||
ret = res.json()
|
||||
im = ret["captchaImage"][21:]
|
||||
result = b64_api(username=USERNAME, password=PASSWORD, b64=im, ID="04897896")
|
||||
return ret["captchaId"],result["data"]["result"]
|
||||
|
||||
def login(username,password):
|
||||
captchaId, ans = recapture()
|
||||
url = URL+"/rest/auth"
|
||||
parm = {
|
||||
"answer": ans.lower(),
|
||||
"captchaId": captchaId,
|
||||
}
|
||||
headers = build_head("post", None)
|
||||
headers.update({
|
||||
"Username": encrypt(username),
|
||||
"Password": encrypt(password),
|
||||
"Logintype": "PC"
|
||||
})
|
||||
res = requests.post(url, headers=headers, params=parm)
|
||||
# print("Status:", res.status_code)
|
||||
ret = res.json()
|
||||
# print("Response:", ret)
|
||||
if ret["status"] == "fail":
|
||||
return None
|
||||
else:
|
||||
return ret["data"]["token"]
|
||||
|
||||
def generate_uuid():
|
||||
hex_digits = '0123456789abcdef'
|
||||
e = [random.choice(hex_digits) for _ in range(36)]
|
||||
e[14] = '4'
|
||||
e[19] = hex_digits[(int(e[19], 16) & 0x3) | 0x8]
|
||||
for i in [8, 13, 18, 23]:
|
||||
e[i] = '-'
|
||||
return ''.join(e)
|
||||
|
||||
def g(e: str):
|
||||
uuid = generate_uuid()
|
||||
timestamp = int(time.time() * 1000)
|
||||
r = f"seat::{uuid}::{timestamp}::{e.upper()}"
|
||||
secret_key = b"leos3cr3t"
|
||||
hmac_obj = hmac.new(secret_key, r.encode('utf-8'), hashlib.sha256)
|
||||
request_key = hmac_obj.hexdigest()
|
||||
return {
|
||||
"id": uuid,
|
||||
"date": timestamp,
|
||||
"requestKey": request_key
|
||||
}
|
||||
|
||||
def build_head(e: str,token:str):
|
||||
sig = g(e)
|
||||
headers = {
|
||||
"Authorization": token,
|
||||
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36",
|
||||
"X-hmac-request-key": sig["requestKey"],
|
||||
"X-request-date": str(sig["date"]),
|
||||
"X-request-id": sig["id"]
|
||||
}
|
||||
if token is None:
|
||||
headers.pop("Authorization")
|
||||
return headers
|
||||
|
||||
def get_floor_data(token: str,buildingId= "1"):
|
||||
date = datetime.now().strftime("%Y-%m-%d") # 获取当前日期
|
||||
url = f"{URL}/rest/v2/room/stats2/{buildingId}/{date}"
|
||||
params = {
|
||||
"buildingId": buildingId,
|
||||
"date": date,
|
||||
"token": token
|
||||
}
|
||||
headers = build_head("get",token)
|
||||
|
||||
response = requests.get(url, headers=headers, params=params)
|
||||
|
||||
print("Status:", response.status_code)
|
||||
res = response.json()
|
||||
if res["status"] != "success":
|
||||
print("Error:", res)
|
||||
return -1
|
||||
else:
|
||||
ret = []
|
||||
for room in res["data"]:
|
||||
ret.append({"roomId": room["roomId"], "room": room["room"], "free": room["free"], "inUse": room["inUse"], "totalSeats": room["totalSeats"]})
|
||||
# print(f"Room ID: {room['roomId']}, Name: {room['room']}, free: {room['free']}, inUse: {room['inUse']}, total: {room['totalSeats']}")
|
||||
return ret
|
||||
|
||||
def get_room_data(token: str,id:str = "10"):
|
||||
date = datetime.now().strftime("%Y-%m-%d") # 获取当前日期
|
||||
# 替换为目标接口地址
|
||||
print(date)
|
||||
url = f"{URL}/rest/v2/room/layoutByDate/{id}/{date}"
|
||||
params = {
|
||||
"id": id,
|
||||
"date": date,
|
||||
"token": token
|
||||
}
|
||||
|
||||
sig = g("get")
|
||||
headers = {
|
||||
"Authorization": token,
|
||||
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36",
|
||||
"X-hmac-request-key": sig["requestKey"],
|
||||
"X-request-date": str(sig["date"]),
|
||||
"X-request-id": sig["id"]
|
||||
}
|
||||
|
||||
response = requests.get(url, headers=headers, params=params)
|
||||
|
||||
print("Status:", response.status_code)
|
||||
ret = response.json()
|
||||
if ret["status"] != "success":
|
||||
print("Error:", ret)
|
||||
return -1
|
||||
else:
|
||||
print("Data:", ret["data"]["name"])
|
||||
print("Response:", )
|
||||
|
||||
def send_message(msg):
|
||||
print(sc_send(TOKEN, "图书馆座位", msg))
|
||||
|
||||
def main(dep=0):
|
||||
if dep>3:
|
||||
print("无法获取数据!")
|
||||
send_message("无法获取数据!")
|
||||
return
|
||||
years = [2021, 2022, 2023, 2024]
|
||||
house = []
|
||||
classes = [1,2,3]
|
||||
num = range(1,21)
|
||||
token = None
|
||||
try:
|
||||
print("正在尝试登录...")
|
||||
tried =0
|
||||
while token is None and tried <= 5:
|
||||
id = UID
|
||||
# id = str(random.choice(years)) + random.choice(house) + str(random.choice(classes)) + str(random.choice(num)).zfill(2)
|
||||
token = login(id,PWD)
|
||||
if token is None:
|
||||
print("登陆失败:",token)
|
||||
time.sleep(random.randint(10, 30))
|
||||
tried += 1
|
||||
if token is None:
|
||||
print("登录失败,请检查账号密码或网络连接。")
|
||||
main(dep+1)
|
||||
return
|
||||
print("登录成功,Token:", token)
|
||||
data = get_floor_data(token, "1") # 获取一楼数据
|
||||
if data == -1:
|
||||
print("获取数据失败,请检查网络连接或Token是否有效。")
|
||||
main(dep+1)
|
||||
else:
|
||||
ret = []
|
||||
for room in data:
|
||||
if room["free"] > 0:
|
||||
ret.append(room)
|
||||
if ret:
|
||||
msg = "|区域|空座|占用率|\n|-|-|-|\n"
|
||||
for room in ret:
|
||||
msg += f"|{room['room']}|{room['free']}|{1-room['free']/room['totalSeats']:0.2f}|\n"
|
||||
send_message(msg)
|
||||
except Exception as e:
|
||||
print("发生错误:", e)
|
||||
main(dep+1)
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
Binary file not shown.
Binary file not shown.
104
pinyin/gen.py
104
pinyin/gen.py
@ -1,53 +1,53 @@
|
||||
t='''毕思淼
|
||||
毕一聪
|
||||
丛金旺
|
||||
崔子豪
|
||||
樊乐天
|
||||
高镆
|
||||
黄卓琳
|
||||
姜樱楠
|
||||
焦祺
|
||||
李柏畅
|
||||
李南卓阳
|
||||
李善伊
|
||||
李怡萱
|
||||
李语恒
|
||||
刘宇航
|
||||
刘雨鑫
|
||||
刘卓
|
||||
娄晴
|
||||
洛艺伟
|
||||
马卉冉
|
||||
潘一鸣
|
||||
庞惠铭
|
||||
乔旺源
|
||||
沈洁
|
||||
宋佳怡
|
||||
宋雨蔓
|
||||
宋智宪
|
||||
苏振宇
|
||||
王梁宇
|
||||
王明仁
|
||||
王耀增
|
||||
王子来
|
||||
吴庆波
|
||||
徐子灏
|
||||
阎展博
|
||||
杨颜聪
|
||||
于诗澳
|
||||
于世函
|
||||
张濠亿
|
||||
张日昊
|
||||
张姝肜
|
||||
张文桦
|
||||
张潇艺
|
||||
张晓轩
|
||||
张妍
|
||||
周含笑
|
||||
周巧冉'''
|
||||
from pypinyin import pinyin
|
||||
from pypinyin import Style
|
||||
l=t.splitlines()
|
||||
for text in l:
|
||||
tem=pinyin(text,style=Style.FIRST_LETTER)
|
||||
t='''毕思淼
|
||||
毕一聪
|
||||
丛金旺
|
||||
崔子豪
|
||||
樊乐天
|
||||
高镆
|
||||
黄卓琳
|
||||
姜樱楠
|
||||
焦祺
|
||||
李柏畅
|
||||
李南卓阳
|
||||
李善伊
|
||||
李怡萱
|
||||
李语恒
|
||||
刘宇航
|
||||
刘雨鑫
|
||||
刘卓
|
||||
娄晴
|
||||
洛艺伟
|
||||
马卉冉
|
||||
潘一鸣
|
||||
庞惠铭
|
||||
乔旺源
|
||||
沈洁
|
||||
宋佳怡
|
||||
宋雨蔓
|
||||
宋智宪
|
||||
苏振宇
|
||||
王梁宇
|
||||
王明仁
|
||||
王耀增
|
||||
王子来
|
||||
吴庆波
|
||||
徐子灏
|
||||
阎展博
|
||||
杨颜聪
|
||||
于诗澳
|
||||
于世函
|
||||
张濠亿
|
||||
张日昊
|
||||
张姝肜
|
||||
张文桦
|
||||
张潇艺
|
||||
张晓轩
|
||||
张妍
|
||||
周含笑
|
||||
周巧冉'''
|
||||
from pypinyin import pinyin
|
||||
from pypinyin import Style
|
||||
l=t.splitlines()
|
||||
for text in l:
|
||||
tem=pinyin(text,style=Style.FIRST_LETTER)
|
||||
print(''.join([i[0] for i in tem]))
|
||||
56
rand/main.py
56
rand/main.py
@ -1,29 +1,29 @@
|
||||
from random import randint
|
||||
|
||||
bgn,end=[int(i) for i in input("Option: Input random area(like 21-43): ").split("-")]
|
||||
obj=int(input("Option: Amount: "))
|
||||
repeat=input("Option: Allow repeat:\nAccept: T(true) (defalt), F(false)\n").lower()
|
||||
if repeat == "":
|
||||
repeat=True
|
||||
else:
|
||||
if repeat in ["t","true"]:
|
||||
repeat=True
|
||||
elif repeat in ["f","false"]:
|
||||
repeat=False
|
||||
else:
|
||||
input("Unsupported option.")
|
||||
l=[]
|
||||
if repeat:
|
||||
l=[randint(bgn,end) for i in range(obj)]
|
||||
else:
|
||||
i=0
|
||||
while len(l)<obj and i<500:
|
||||
t=randint(bgn,end)
|
||||
i+=1
|
||||
if t not in l:
|
||||
l.append(t)
|
||||
|
||||
print(l)
|
||||
for i in l[1:]:
|
||||
print(randint(bgn,end),end=", ")
|
||||
from random import randint
|
||||
|
||||
bgn,end=[int(i) for i in input("Option: Input random area(like 21-43): ").split("-")]
|
||||
obj=int(input("Option: Amount: "))
|
||||
repeat=input("Option: Allow repeat:\nAccept: T(true) (defalt), F(false)\n").lower()
|
||||
if repeat == "":
|
||||
repeat=True
|
||||
else:
|
||||
if repeat in ["t","true"]:
|
||||
repeat=True
|
||||
elif repeat in ["f","false"]:
|
||||
repeat=False
|
||||
else:
|
||||
input("Unsupported option.")
|
||||
l=[]
|
||||
if repeat:
|
||||
l=[randint(bgn,end) for i in range(obj)]
|
||||
else:
|
||||
i=0
|
||||
while len(l)<obj and i<500:
|
||||
t=randint(bgn,end)
|
||||
i+=1
|
||||
if t not in l:
|
||||
l.append(t)
|
||||
|
||||
print(l)
|
||||
for i in l[1:]:
|
||||
print(randint(bgn,end),end=", ")
|
||||
print(l[0])
|
||||
206
recode/recode.py
206
recode/recode.py
@ -1,103 +1,103 @@
|
||||
from sys import argv
|
||||
from os.path import isfile, isdir
|
||||
from os import mkdir
|
||||
from json import dump, load
|
||||
HELP = '''
|
||||
Usage: recode.py <options>/<filename(s)>
|
||||
Options:
|
||||
If options is specified, program will only save configs.
|
||||
|
||||
-i: input file code. (eg. utf-8) (Default: test all known codes)
|
||||
-o: output file code. (Default: utf-8)
|
||||
-c: codes that try to convert from. (Default: test all known codes)
|
||||
split by ','. (eg. utf-8,gbk,gb2312)
|
||||
-r: save the output file in the specified directory. (Default: out)
|
||||
-s: show all known codes. (Don't use this with others)
|
||||
'''
|
||||
OPTIONS = ["-i", "-o", "-c", "-s", "-r"]
|
||||
|
||||
CODES = ['ascii', 'big5', 'big5hkscs', 'cp037', 'cp273', 'cp424', 'cp437', 'cp500', 'cp720', 'cp737', 'cp775', 'cp850', 'cp852', 'cp855', 'cp856', 'cp857', 'cp858', 'cp860', 'cp861', 'cp862', 'cp863', 'cp864', 'cp865', 'cp866', 'cp869', 'cp874', 'cp875', 'cp932', 'cp949', 'cp950', 'cp1006', 'cp1026', 'cp1125', 'cp1140', 'cp1250', 'cp1251', 'cp1252', 'cp1253', 'cp1254', 'cp1255', 'cp1256', 'cp1257', 'cp1258', 'euc_jp', 'euc_jis_2004', 'euc_jisx0213', 'euc_kr', 'gb2312', 'gbk', 'gb18030', 'hz', 'iso2022_jp', 'iso2022_jp_1', 'iso2022_jp_2', 'iso2022_jp_2004',
|
||||
'iso2022_jp_3', 'iso2022_jp_ext', 'iso2022_kr', 'latin_1', 'iso8859_2', 'iso8859_3', 'iso8859_4', 'iso8859_5', 'iso8859_6', 'iso8859_7', 'iso8859_8', 'iso8859_9', 'iso8859_10', 'iso8859_11', 'iso8859_13', 'iso8859_14', 'iso8859_15', 'iso8859_16', 'johab', 'koi8_r', 'koi8_t', 'koi8_u', 'kz1048', 'mac_cyrillic', 'mac_greek', 'mac_iceland', 'mac_latin2', 'mac_roman', 'mac_turkish', 'ptcp154', 'shift_jis', 'shift_jis_2004', 'shift_jisx0213', 'utf_32', 'utf_32_be', 'utf_32_le', 'utf_16', 'utf_16_be', 'utf_16_le', 'utf_7', 'utf_8', 'utf_8_sig']
|
||||
DEFALT = {'ipt': None, 'opt': 'utf-8', 'test': None, 'write': 'out'}
|
||||
|
||||
|
||||
def setOption(arg):
|
||||
if arg[0] == '-s':
|
||||
for i in CODES:
|
||||
print("%15s" % i, end=' ')
|
||||
return
|
||||
opt = arg[::2]
|
||||
val = arg[1:][::2]
|
||||
option = DEFALT.copy()
|
||||
trans = {'-i': 'ipt', '-o': 'opt', '-c': 'test', "-r": "write"}
|
||||
for o, v in zip(opt, val):
|
||||
if o == '-c':
|
||||
option[trans[o]] = v.split(',')
|
||||
else:
|
||||
option[trans[o]] = v
|
||||
with open("config.json", "w") as f:
|
||||
dump(option, f)
|
||||
|
||||
|
||||
def main(files):
|
||||
if isfile("config.json"):
|
||||
try:
|
||||
with open("config.json", "r") as f:
|
||||
config = load(f)
|
||||
except Exception:
|
||||
print("Can't read config file.")
|
||||
config = DEFALT
|
||||
else:
|
||||
print("No config file provided.")
|
||||
config = DEFALT
|
||||
|
||||
codes = CODES if config["test"] is None else config["test"]
|
||||
outcode = config["opt"]
|
||||
outdir = config["write"]
|
||||
|
||||
if not isdir(outdir):
|
||||
mkdir(outdir)
|
||||
|
||||
for file in files:
|
||||
if isfile(outdir+'/'+file):
|
||||
print(f"File '{outdir+'/'+file} exists. Ignore.")
|
||||
continue
|
||||
if config["ipt"] is None:
|
||||
for code in codes:
|
||||
if recode(file, outdir, code, outcode, config["write"]):
|
||||
break
|
||||
else:
|
||||
if not recode(file, outdir, config["ipt"], outcode):
|
||||
print("Could not convert '%s' from '%s' to '%s'" %
|
||||
(file, config["ipt"], outcode))
|
||||
else:
|
||||
print(f"Success to convert {file}")
|
||||
|
||||
|
||||
def recode(file, opt, src, to) -> bool:
|
||||
try:
|
||||
with open(file, 'r', encoding=src) as f:
|
||||
tem = f.read()
|
||||
except KeyboardInterrupt:
|
||||
exit(2)
|
||||
except Exception:
|
||||
print("Can't open file.")
|
||||
return False
|
||||
try:
|
||||
with open(opt+'/'+file, 'w', encoding=to) as f:
|
||||
f.write(tem)
|
||||
except KeyboardInterrupt:
|
||||
exit(2)
|
||||
except Exception:
|
||||
print("Can't write file.")
|
||||
return True
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if len(argv) == 1:
|
||||
print(HELP)
|
||||
exit(1)
|
||||
elif argv[1] in OPTIONS:
|
||||
setOption(argv[1:])
|
||||
else:
|
||||
main(argv[1:])
|
||||
from sys import argv
|
||||
from os.path import isfile, isdir
|
||||
from os import mkdir
|
||||
from json import dump, load
|
||||
HELP = '''
|
||||
Usage: recode.py <options>/<filename(s)>
|
||||
Options:
|
||||
If options is specified, program will only save configs.
|
||||
|
||||
-i: input file code. (eg. utf-8) (Default: test all known codes)
|
||||
-o: output file code. (Default: utf-8)
|
||||
-c: codes that try to convert from. (Default: test all known codes)
|
||||
split by ','. (eg. utf-8,gbk,gb2312)
|
||||
-r: save the output file in the specified directory. (Default: out)
|
||||
-s: show all known codes. (Don't use this with others)
|
||||
'''
|
||||
OPTIONS = ["-i", "-o", "-c", "-s", "-r"]
|
||||
|
||||
CODES = ['ascii', 'big5', 'big5hkscs', 'cp037', 'cp273', 'cp424', 'cp437', 'cp500', 'cp720', 'cp737', 'cp775', 'cp850', 'cp852', 'cp855', 'cp856', 'cp857', 'cp858', 'cp860', 'cp861', 'cp862', 'cp863', 'cp864', 'cp865', 'cp866', 'cp869', 'cp874', 'cp875', 'cp932', 'cp949', 'cp950', 'cp1006', 'cp1026', 'cp1125', 'cp1140', 'cp1250', 'cp1251', 'cp1252', 'cp1253', 'cp1254', 'cp1255', 'cp1256', 'cp1257', 'cp1258', 'euc_jp', 'euc_jis_2004', 'euc_jisx0213', 'euc_kr', 'gb2312', 'gbk', 'gb18030', 'hz', 'iso2022_jp', 'iso2022_jp_1', 'iso2022_jp_2', 'iso2022_jp_2004',
|
||||
'iso2022_jp_3', 'iso2022_jp_ext', 'iso2022_kr', 'latin_1', 'iso8859_2', 'iso8859_3', 'iso8859_4', 'iso8859_5', 'iso8859_6', 'iso8859_7', 'iso8859_8', 'iso8859_9', 'iso8859_10', 'iso8859_11', 'iso8859_13', 'iso8859_14', 'iso8859_15', 'iso8859_16', 'johab', 'koi8_r', 'koi8_t', 'koi8_u', 'kz1048', 'mac_cyrillic', 'mac_greek', 'mac_iceland', 'mac_latin2', 'mac_roman', 'mac_turkish', 'ptcp154', 'shift_jis', 'shift_jis_2004', 'shift_jisx0213', 'utf_32', 'utf_32_be', 'utf_32_le', 'utf_16', 'utf_16_be', 'utf_16_le', 'utf_7', 'utf_8', 'utf_8_sig']
|
||||
DEFALT = {'ipt': None, 'opt': 'utf-8', 'test': None, 'write': 'out'}
|
||||
|
||||
|
||||
def setOption(arg):
|
||||
if arg[0] == '-s':
|
||||
for i in CODES:
|
||||
print("%15s" % i, end=' ')
|
||||
return
|
||||
opt = arg[::2]
|
||||
val = arg[1:][::2]
|
||||
option = DEFALT.copy()
|
||||
trans = {'-i': 'ipt', '-o': 'opt', '-c': 'test', "-r": "write"}
|
||||
for o, v in zip(opt, val):
|
||||
if o == '-c':
|
||||
option[trans[o]] = v.split(',')
|
||||
else:
|
||||
option[trans[o]] = v
|
||||
with open("config.json", "w") as f:
|
||||
dump(option, f)
|
||||
|
||||
|
||||
def main(files):
|
||||
if isfile("config.json"):
|
||||
try:
|
||||
with open("config.json", "r") as f:
|
||||
config = load(f)
|
||||
except Exception:
|
||||
print("Can't read config file.")
|
||||
config = DEFALT
|
||||
else:
|
||||
print("No config file provided.")
|
||||
config = DEFALT
|
||||
|
||||
codes = CODES if config["test"] is None else config["test"]
|
||||
outcode = config["opt"]
|
||||
outdir = config["write"]
|
||||
|
||||
if not isdir(outdir):
|
||||
mkdir(outdir)
|
||||
|
||||
for file in files:
|
||||
if isfile(outdir+'/'+file):
|
||||
print(f"File '{outdir+'/'+file} exists. Ignore.")
|
||||
continue
|
||||
if config["ipt"] is None:
|
||||
for code in codes:
|
||||
if recode(file, outdir, code, outcode, config["write"]):
|
||||
break
|
||||
else:
|
||||
if not recode(file, outdir, config["ipt"], outcode):
|
||||
print("Could not convert '%s' from '%s' to '%s'" %
|
||||
(file, config["ipt"], outcode))
|
||||
else:
|
||||
print(f"Success to convert {file}")
|
||||
|
||||
|
||||
def recode(file, opt, src, to) -> bool:
|
||||
try:
|
||||
with open(file, 'r', encoding=src) as f:
|
||||
tem = f.read()
|
||||
except KeyboardInterrupt:
|
||||
exit(2)
|
||||
except Exception:
|
||||
print("Can't open file.")
|
||||
return False
|
||||
try:
|
||||
with open(opt+'/'+file, 'w', encoding=to) as f:
|
||||
f.write(tem)
|
||||
except KeyboardInterrupt:
|
||||
exit(2)
|
||||
except Exception:
|
||||
print("Can't write file.")
|
||||
return True
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if len(argv) == 1:
|
||||
print(HELP)
|
||||
exit(1)
|
||||
elif argv[1] in OPTIONS:
|
||||
setOption(argv[1:])
|
||||
else:
|
||||
main(argv[1:])
|
||||
|
||||
@ -1,58 +1,58 @@
|
||||
from sys import argv
|
||||
from os.path import isfile, isdir,abspath
|
||||
from os import mkdir
|
||||
from chardet import detect
|
||||
from colorama import init,Fore
|
||||
HELP = '''
|
||||
Usage: recode.py <options>/<filename(s)>
|
||||
'''
|
||||
TARGET = 'utf-8'
|
||||
OUTDIR = "Output"
|
||||
|
||||
|
||||
def main(files):
|
||||
if not isdir(OUTDIR):
|
||||
mkdir(OUTDIR)
|
||||
|
||||
for file in files:
|
||||
path = abspath(file)
|
||||
path = path.replace("\\", "/")
|
||||
path = path.split('/')
|
||||
path = '/'.join(path[:-1])+"/"+OUTDIR+"/"+path[-1]
|
||||
if isfile(path):
|
||||
print(Fore.YELLOW+f"WARN: File '{path} exists. Ignore.")
|
||||
continue
|
||||
recode(file,path)
|
||||
|
||||
|
||||
def recode(file,path):
|
||||
try:
|
||||
with open(file, 'rb') as f:
|
||||
tem = f.read()
|
||||
except Exception as e:
|
||||
print(Fore.RED+f"ERROR: Can't open file '{file}'")
|
||||
return
|
||||
ret = detect(tem)
|
||||
if ret["encoding"] is None:
|
||||
print(Fore.RED+"ERROR: Cannot detect encoding of `%s`" % file)
|
||||
return
|
||||
|
||||
with open(file, 'r',encoding=ret["encoding"]) as f:
|
||||
tem = f.read()
|
||||
|
||||
if ret['confidence'] < 0.8:
|
||||
print(Fore.YELLOW+"WARN: File `%s` confidence is lower than 0.8. Recognized as `%s`."%(file,ret["encoding"]))
|
||||
|
||||
with open(path, 'w', encoding=TARGET) as f:
|
||||
f.write(tem)
|
||||
print(Fore.LIGHTBLUE_EX+"INFO: Success for `%s` with confidence %0.1f%%"%(file,ret["confidence"]*100))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
init(autoreset=True)
|
||||
if len(argv) == 1:
|
||||
print(HELP)
|
||||
else:
|
||||
main(argv[1:])
|
||||
print("------------------------")
|
||||
input("Press enter to exit")
|
||||
from sys import argv
|
||||
from os.path import isfile, isdir,abspath
|
||||
from os import mkdir
|
||||
from chardet import detect
|
||||
from colorama import init,Fore
|
||||
HELP = '''
|
||||
Usage: recode.py <options>/<filename(s)>
|
||||
'''
|
||||
TARGET = 'utf-8'
|
||||
OUTDIR = "Output"
|
||||
|
||||
|
||||
def main(files):
|
||||
if not isdir(OUTDIR):
|
||||
mkdir(OUTDIR)
|
||||
|
||||
for file in files:
|
||||
path = abspath(file)
|
||||
path = path.replace("\\", "/")
|
||||
path = path.split('/')
|
||||
path = '/'.join(path[:-1])+"/"+OUTDIR+"/"+path[-1]
|
||||
if isfile(path):
|
||||
print(Fore.YELLOW+f"WARN: File '{path} exists. Ignore.")
|
||||
continue
|
||||
recode(file,path)
|
||||
|
||||
|
||||
def recode(file,path):
|
||||
try:
|
||||
with open(file, 'rb') as f:
|
||||
tem = f.read()
|
||||
except Exception as e:
|
||||
print(Fore.RED+f"ERROR: Can't open file '{file}'")
|
||||
return
|
||||
ret = detect(tem)
|
||||
if ret["encoding"] is None:
|
||||
print(Fore.RED+"ERROR: Cannot detect encoding of `%s`" % file)
|
||||
return
|
||||
|
||||
with open(file, 'r',encoding=ret["encoding"]) as f:
|
||||
tem = f.read()
|
||||
|
||||
if ret['confidence'] < 0.8:
|
||||
print(Fore.YELLOW+"WARN: File `%s` confidence is lower than 0.8. Recognized as `%s`."%(file,ret["encoding"]))
|
||||
|
||||
with open(path, 'w', encoding=TARGET) as f:
|
||||
f.write(tem)
|
||||
print(Fore.LIGHTBLUE_EX+"INFO: Success for `%s` with confidence %0.1f%%"%(file,ret["confidence"]*100))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
init(autoreset=True)
|
||||
if len(argv) == 1:
|
||||
print(HELP)
|
||||
else:
|
||||
main(argv[1:])
|
||||
print("------------------------")
|
||||
input("Press enter to exit")
|
||||
|
||||
Binary file not shown.
62
video/cut.py
62
video/cut.py
@ -1,32 +1,32 @@
|
||||
from sys import argv
|
||||
from subprocess import run
|
||||
from os import system
|
||||
|
||||
if len(argv) != 2:
|
||||
print("Usage: <file>")
|
||||
exit(1)
|
||||
file = argv[1]
|
||||
tem=file.split(".")
|
||||
name = ".".join(tem[:-1])
|
||||
o = tem[-1]
|
||||
bgn = input("bgn: ")
|
||||
if bgn=="":
|
||||
bgn="0"
|
||||
to = input("to: ")
|
||||
cmd = [
|
||||
r'E:\green\ffmpeg\bin\ffmpeg.exe',
|
||||
'-i',
|
||||
file,
|
||||
'-ss',
|
||||
bgn,
|
||||
'-to',
|
||||
to,
|
||||
'-c',
|
||||
'copy',
|
||||
name+"_cut."+o
|
||||
]
|
||||
print(cmd)
|
||||
# run("pause")
|
||||
ret = run(cmd)
|
||||
print("ffmpeg finished with code",ret.returncode)
|
||||
from sys import argv
|
||||
from subprocess import run
|
||||
from os import system
|
||||
|
||||
if len(argv) != 2:
|
||||
print("Usage: <file>")
|
||||
exit(1)
|
||||
file = argv[1]
|
||||
tem=file.split(".")
|
||||
name = ".".join(tem[:-1])
|
||||
o = tem[-1]
|
||||
bgn = input("bgn: ")
|
||||
if bgn=="":
|
||||
bgn="0"
|
||||
to = input("to: ")
|
||||
cmd = [
|
||||
r'E:\green\ffmpeg\bin\ffmpeg.exe',
|
||||
'-i',
|
||||
file,
|
||||
'-ss',
|
||||
bgn,
|
||||
'-to',
|
||||
to,
|
||||
'-c',
|
||||
'copy',
|
||||
name+"_cut."+o
|
||||
]
|
||||
print(cmd)
|
||||
# run("pause")
|
||||
ret = run(cmd)
|
||||
print("ffmpeg finished with code",ret.returncode)
|
||||
system("pause")
|
||||
148
wjx/main.py
148
wjx/main.py
@ -1,75 +1,75 @@
|
||||
from requests import Response,Session
|
||||
from re import search
|
||||
from json import dumps
|
||||
|
||||
headers = {
|
||||
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.42'
|
||||
}
|
||||
s=Session()
|
||||
|
||||
def chk(resp:Response):
|
||||
if resp.status_code != 200:
|
||||
print("Error: %d" % resp.status_code)
|
||||
exit(1)
|
||||
return resp.text
|
||||
|
||||
def get(url,**kwargs):
|
||||
ret = s.get(url,allow_redirects=False,headers=headers,**kwargs)
|
||||
jar = ret.cookies
|
||||
if ret.status_code == 302:
|
||||
url2 = ret.headers['Location']
|
||||
return get(url2, cookies=jar)
|
||||
elif ret.status_code != 200:
|
||||
print("Error: %d" % ret.status_code)
|
||||
exit(1)
|
||||
return ret
|
||||
|
||||
def login(username, password):
|
||||
# 问卷星竟然明文发送密码
|
||||
ret = chk(s.get("https://www.wjx.cn/login.aspx"))
|
||||
v1 = search('(?<=(<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value=")).+(?=(" />))',ret)
|
||||
if v1 is not None:
|
||||
v1 = v1.group()
|
||||
v2 = search('(?<=(<input type="hidden" name="__VIEWSTATEGENERATOR" id="__VIEWSTATEGENERATOR" value=")).+(?=(" />))',ret)
|
||||
if v2 is not None:
|
||||
v2 = v2.group()
|
||||
v3 = search('(?<=(<input type="hidden" name="__EVENTVALIDATION" id="__EVENTVALIDATION" value=")).+(?=(" />))',ret)
|
||||
if v3 is not None:
|
||||
v3 = v3.group()
|
||||
print(v1,v2,v3)
|
||||
with open("tmp.html", "w",encoding="utf-8") as f:
|
||||
print(ret,file=f)
|
||||
d={
|
||||
"__VIEWSTATE": v1,
|
||||
"__VIEWSTATEGENERATOR": v2,
|
||||
"__EVENTVALIDATION": v3,
|
||||
"UserName": username,
|
||||
"Password": password,
|
||||
"LoginButton": "登录"
|
||||
}
|
||||
# d={
|
||||
# "__VIEWSTATE": "/wEPDwULLTIxMTQ1NzY4NzFkGAEFHl9fQ29udHJvbHNSZXF1aXJlUG9zdEJhY2tLZXlfXxYBBQpSZW1lbWJlck1ldLwU4qgz33Rji8zou8eAENNib4k=",
|
||||
# "__VIEWSTATEGENERATOR":"C2EE9ABB",
|
||||
# "__EVENTVALIDATION": "/wEdAAfxrqR6nVOy3mBYlwdwNQ3ZR1LBKX1P1xh290RQyTesRRHS0B3lkDg8wcTlzQR027xRgZ0GCHKgt6QG86UlMSuIXArz/WCefbk6V2VE3Ih52ScdcjStD50aK/ZrfWs/uQXcqaj6i4HaaYTcyD0yJuxuNMxKZaXzJnI0VXVv9OL2HZrk5tk=",
|
||||
# "UserName": username,
|
||||
# "Password": password,
|
||||
# "LoginButton": "登录"
|
||||
# }
|
||||
ret = s.post("https://www.wjx.cn/Login.aspx",json=dumps(d))
|
||||
ret.raise_for_status()
|
||||
|
||||
def getlist(id):
|
||||
ret = s.get(
|
||||
"https://www.wjx.cn/wjx/activitystat/viewstatsummary.aspx",
|
||||
params={"activity":id},
|
||||
headers=headers
|
||||
)
|
||||
ret = chk(ret)
|
||||
find = search(r'(?<=(var ids = "))[\d,]+(?=(";))',ret)
|
||||
assert find is not None,ret
|
||||
return find.group().split(",")
|
||||
|
||||
if __name__ == "__main__":
|
||||
login("flt","**************")
|
||||
print(s.cookies)
|
||||
from requests import Response,Session
|
||||
from re import search
|
||||
from json import dumps
|
||||
|
||||
headers = {
|
||||
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.42'
|
||||
}
|
||||
s=Session()
|
||||
|
||||
def chk(resp:Response):
|
||||
if resp.status_code != 200:
|
||||
print("Error: %d" % resp.status_code)
|
||||
exit(1)
|
||||
return resp.text
|
||||
|
||||
def get(url,**kwargs):
|
||||
ret = s.get(url,allow_redirects=False,headers=headers,**kwargs)
|
||||
jar = ret.cookies
|
||||
if ret.status_code == 302:
|
||||
url2 = ret.headers['Location']
|
||||
return get(url2, cookies=jar)
|
||||
elif ret.status_code != 200:
|
||||
print("Error: %d" % ret.status_code)
|
||||
exit(1)
|
||||
return ret
|
||||
|
||||
def login(username, password):
|
||||
# 问卷星竟然明文发送密码
|
||||
ret = chk(s.get("https://www.wjx.cn/login.aspx"))
|
||||
v1 = search('(?<=(<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value=")).+(?=(" />))',ret)
|
||||
if v1 is not None:
|
||||
v1 = v1.group()
|
||||
v2 = search('(?<=(<input type="hidden" name="__VIEWSTATEGENERATOR" id="__VIEWSTATEGENERATOR" value=")).+(?=(" />))',ret)
|
||||
if v2 is not None:
|
||||
v2 = v2.group()
|
||||
v3 = search('(?<=(<input type="hidden" name="__EVENTVALIDATION" id="__EVENTVALIDATION" value=")).+(?=(" />))',ret)
|
||||
if v3 is not None:
|
||||
v3 = v3.group()
|
||||
print(v1,v2,v3)
|
||||
with open("tmp.html", "w",encoding="utf-8") as f:
|
||||
print(ret,file=f)
|
||||
d={
|
||||
"__VIEWSTATE": v1,
|
||||
"__VIEWSTATEGENERATOR": v2,
|
||||
"__EVENTVALIDATION": v3,
|
||||
"UserName": username,
|
||||
"Password": password,
|
||||
"LoginButton": "登录"
|
||||
}
|
||||
# d={
|
||||
# "__VIEWSTATE": "/wEPDwULLTIxMTQ1NzY4NzFkGAEFHl9fQ29udHJvbHNSZXF1aXJlUG9zdEJhY2tLZXlfXxYBBQpSZW1lbWJlck1ldLwU4qgz33Rji8zou8eAENNib4k=",
|
||||
# "__VIEWSTATEGENERATOR":"C2EE9ABB",
|
||||
# "__EVENTVALIDATION": "/wEdAAfxrqR6nVOy3mBYlwdwNQ3ZR1LBKX1P1xh290RQyTesRRHS0B3lkDg8wcTlzQR027xRgZ0GCHKgt6QG86UlMSuIXArz/WCefbk6V2VE3Ih52ScdcjStD50aK/ZrfWs/uQXcqaj6i4HaaYTcyD0yJuxuNMxKZaXzJnI0VXVv9OL2HZrk5tk=",
|
||||
# "UserName": username,
|
||||
# "Password": password,
|
||||
# "LoginButton": "登录"
|
||||
# }
|
||||
ret = s.post("https://www.wjx.cn/Login.aspx",json=dumps(d))
|
||||
ret.raise_for_status()
|
||||
|
||||
def getlist(id):
|
||||
ret = s.get(
|
||||
"https://www.wjx.cn/wjx/activitystat/viewstatsummary.aspx",
|
||||
params={"activity":id},
|
||||
headers=headers
|
||||
)
|
||||
ret = chk(ret)
|
||||
find = search(r'(?<=(var ids = "))[\d,]+(?=(";))',ret)
|
||||
assert find is not None,ret
|
||||
return find.group().split(",")
|
||||
|
||||
if __name__ == "__main__":
|
||||
login("flt","**************")
|
||||
print(s.cookies)
|
||||
print(getlist("184412487"))
|
||||
22
wjx/tmp.py
22
wjx/tmp.py
@ -1,12 +1,12 @@
|
||||
import requests
|
||||
|
||||
url = "https://www.wjx.cn/login.aspx"
|
||||
|
||||
payload={}
|
||||
headers = {
|
||||
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.42'
|
||||
}
|
||||
|
||||
response = requests.request("GET", url, headers=headers, data=payload)
|
||||
|
||||
import requests
|
||||
|
||||
url = "https://www.wjx.cn/login.aspx"
|
||||
|
||||
payload={}
|
||||
headers = {
|
||||
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.42'
|
||||
}
|
||||
|
||||
response = requests.request("GET", url, headers=headers, data=payload)
|
||||
|
||||
print(response.text)
|
||||
4
zxxk_dl/.gitignore
vendored
4
zxxk_dl/.gitignore
vendored
@ -1,3 +1,3 @@
|
||||
*.html
|
||||
*.pdf
|
||||
*.html
|
||||
*.pdf
|
||||
*.docx
|
||||
Reference in New Issue
Block a user